I made a few claims in the past stating that the average size of pull requests went up by an order of magnitude. I largely based it on hallway conversations with developers at Lunar Logic.
It turns out, the actual data is not that hard to check. Aaaand I was wrong.
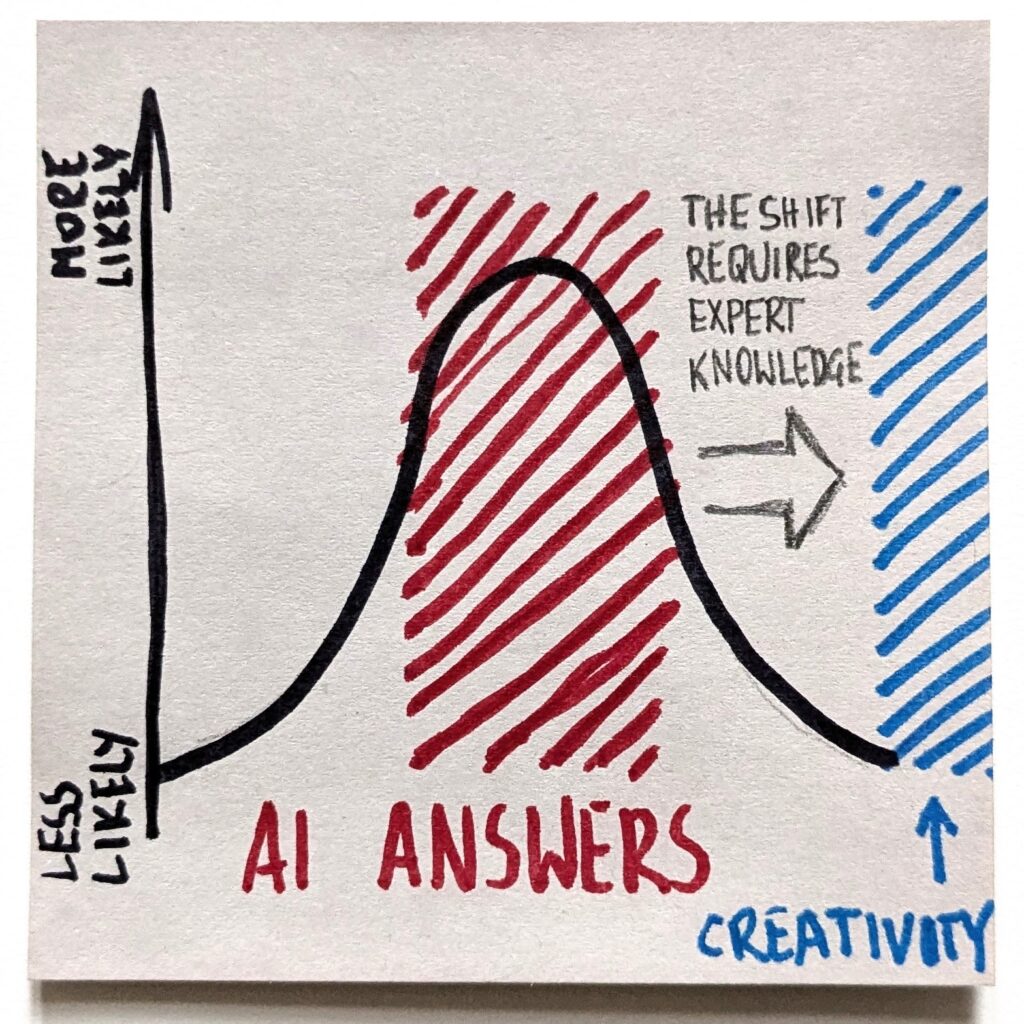
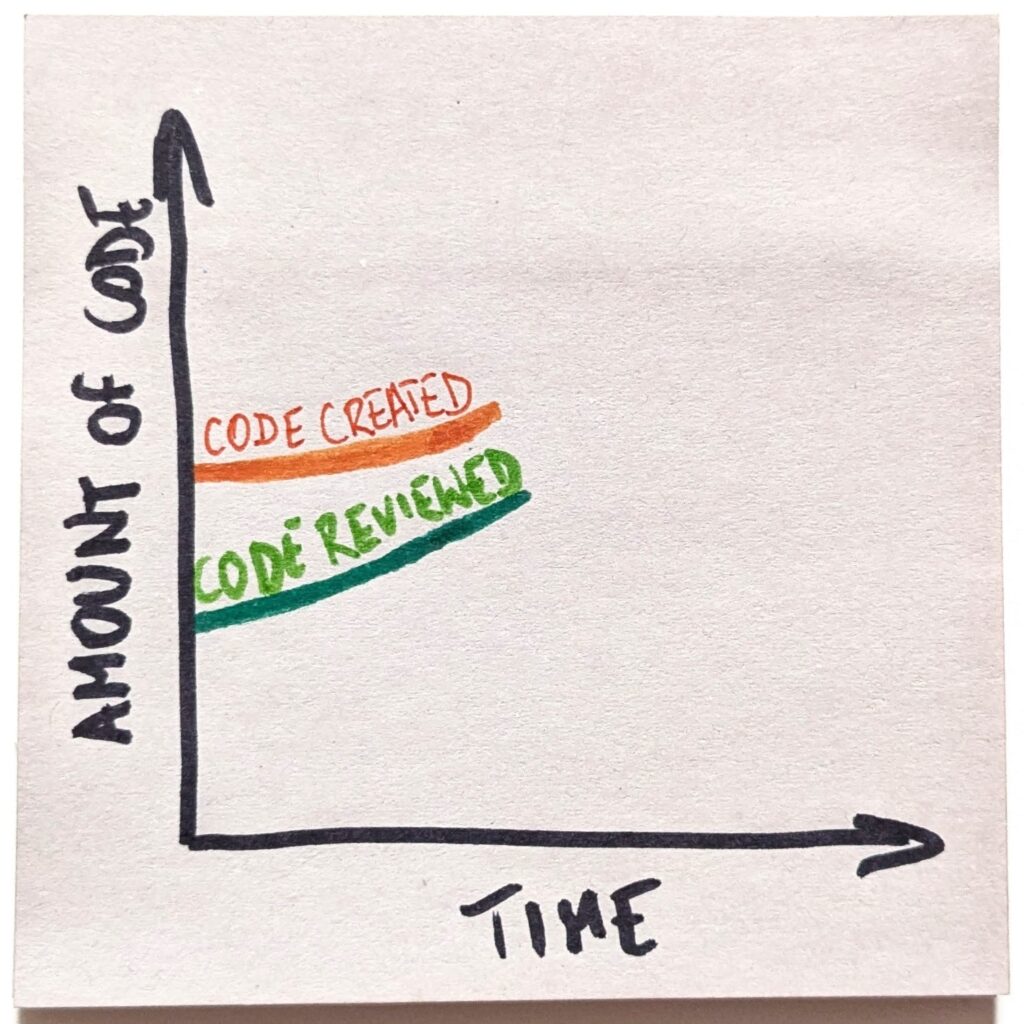
AI Effect in PR Size
We pulled data from two very similar projects in terms of complexity, effort, and team size. Both codebases started greenfield and covered a few hundred pull requests in the analyzed period. There was even an overlap across the engineering team. The key difference? How we used AI.
The first project, let’s call it Helpful, happened in the pre-Claude era. While we already used AI to support development, it was predominantly autocomplete with occasional trips to ChatGPT to suggest solutions to pesky problems. All code was managed by developers in real time.
The second gig, I’ll call it Grateful, was full-on Claude. The basic assumption was that none of the code was written by hand. Engineering responsibilities were in context management, prompting, and review.
The bottom line? In an AI-heavy project, average PR size increased by a factor of 3.5.
Yes, I was wrong, but only about the relative scale of the change.
Tiny PRs Have Disappeared
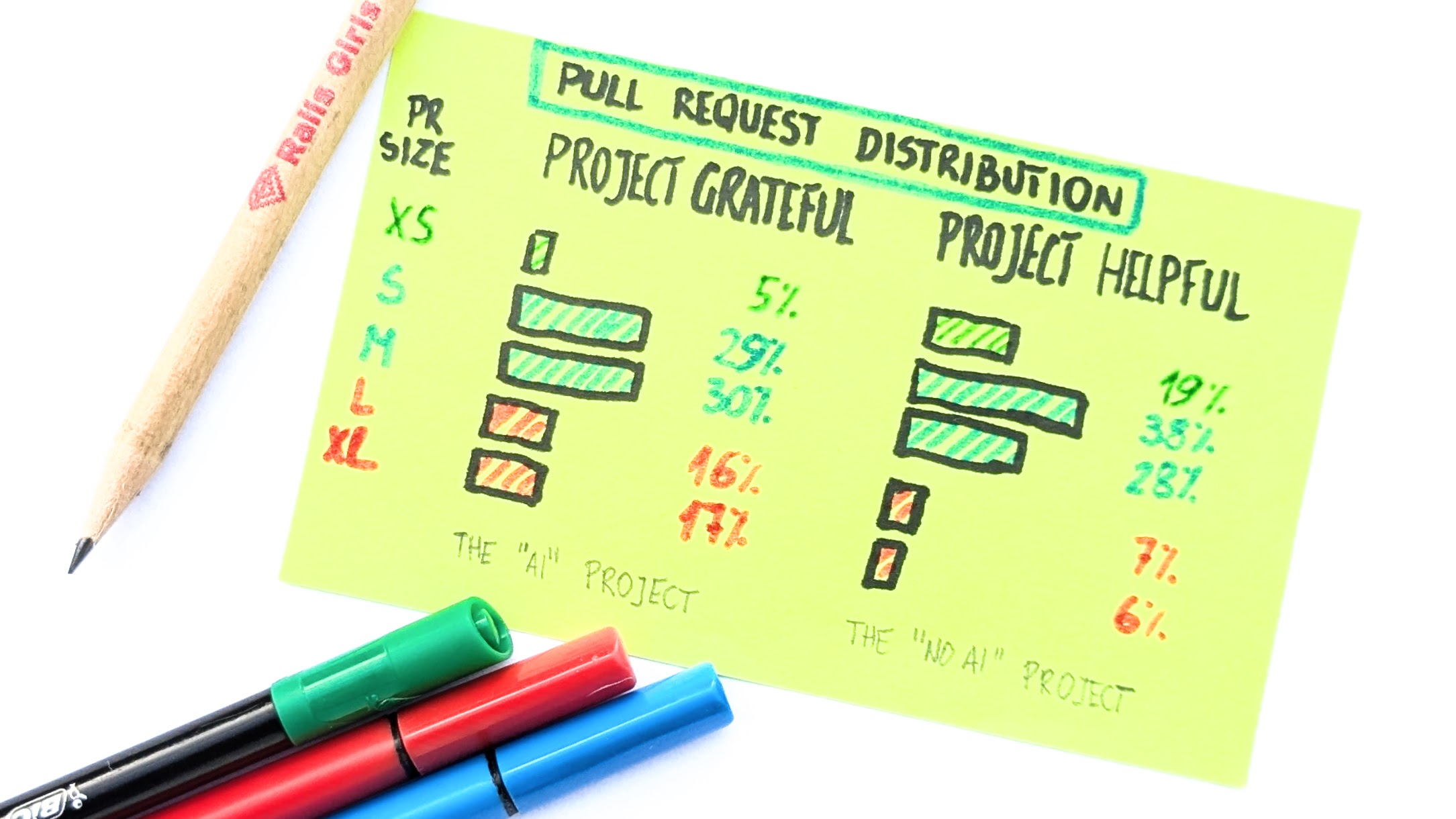
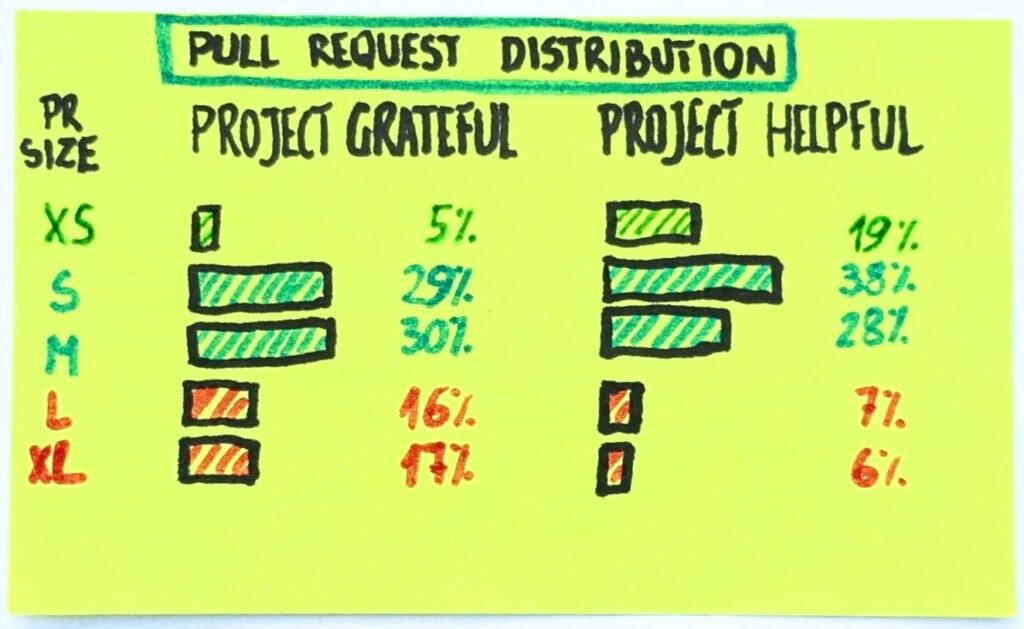
It would be easy to say that AI made us tackle bigger tasks. That’s not what data suggests, though. At least not when we look at the distribution of the PRs. Note: We sum the added and removed lines to calculate the PR size.
The bulk of PRs in both cases are small to medium ones. A few hundred lines of code tops (our cutoff line was 500). It was the bread and butter of engineering work. It still is.
Sure, in Project Helpful (the “no AI” one), these PRs were skewed toward smaller sizes, while in Project Grateful, the center of gravity was 100-200 lines of code heavier. Still, for an engineer familiar with the codebase, that’s not a challenge.
So, how come the average went up that much?
The answer is on the fringes. The smallest pull requests—the proverbial one-liners—all but disappeared. That’s the single most significant change. Tiny PRs were 1 in 5. Now they are 1 in 20.
The whole class of work items that was easiest to review is at risk of extinction. Let’s park this thought. I’ll be back to it soon.
Large PRs Are on the Rise
What we lost from the tiniest bits of work, we make up for with the largest.
There are almost 3 times as many large PRs.
The 90th percentile size increased 3x, from 600 lines of code to 1799 lines of code.
The outliers inflated even more—the largest PR in Project Grateful was 30k+ lines of code, almost 7 times bigger than its equivalent in Project Helpful.
Big just got bigger. And we get more of it, too.
Still, these chunks of code do not dominate the work. Definitely not just yet. However, there are enough of them to start paying attention.
Coincidentally, this is a class of items that is the most challenging for a reviewer. By now, you can probably guess where it is heading.
The Effects of Processing 3 Times as Many Lines of Code
No matter how I slice the data, it seems that we now deal with tasks that are roughly three times as big as they used to be.
The average PR size went up from 232 to 817 LoC—a 3.5x increase.
The median PR size went up from 66 to 210 LoC—a 3.2x increase.
The percentage of big and large PRs went up from 13% to 33%—a 2.5x increase.
Long story short, our brains process three times as much information per task as they used to. Common sense suggests that the review can’t be as thorough as it was when done in smaller bits.
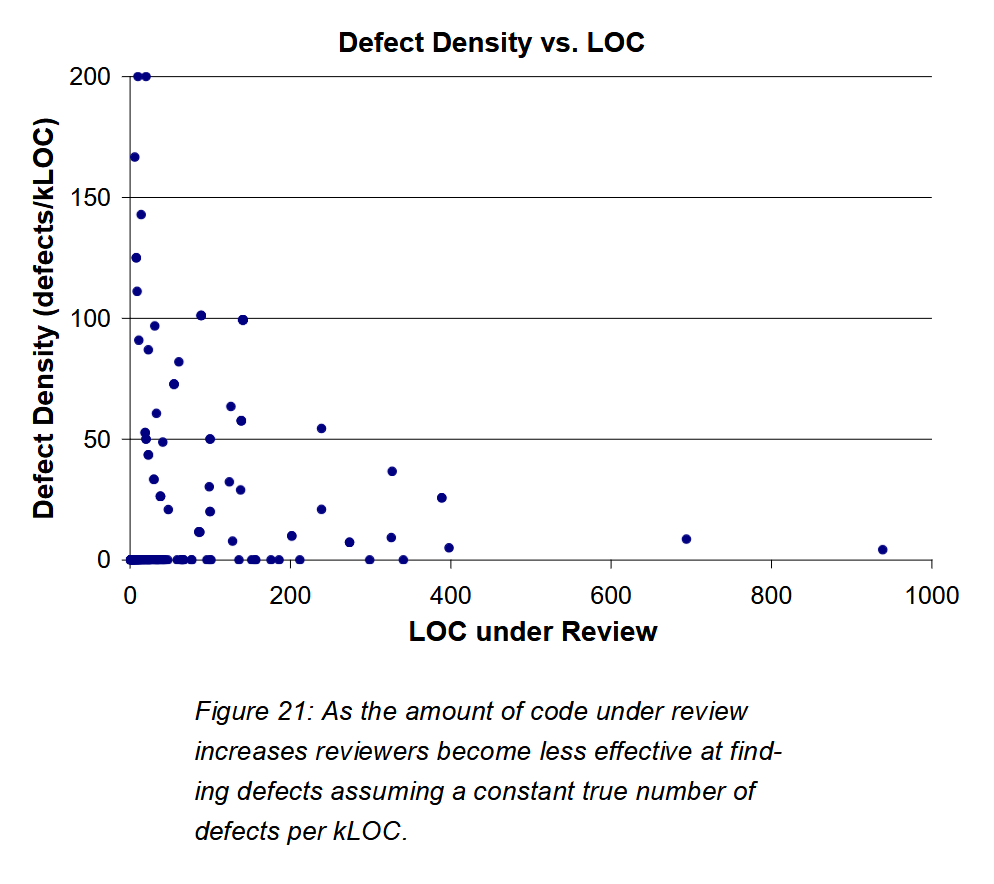
Research seems to concur. Well-recognized Smart Bear/Cisco study advises keeping pull request size below 200 lines. Above that size, reviewers start overlooking the issues.
“Reviewers are most effective at reviewing small amounts of code. Anything below 200 lines produces a relatively high rate of defects, often several times the average. After that the results trail off considerably; no review larger than 250 lines produced more than 37 defects per 1000 lines of code.”
Executive summary: Heavy use of AI makes individual chunks of work larger, and thus, overall quality drops.
Quality Drop Is Not Inevitable But Highly Likely
If we consider the changes, none of them seems inevitable. I mean, we can tell Claude Code to work in smaller chunks so it’s more convenient to review. Heck, we can make it use the annotation technique advised by the Smart Bear study. As a result, we should sustain most of the quality standards.
There’s only one issue. We won’t do any of these.
It would require engineers to artificially throttle their coding agents. It would mean more back-and-forth between humans and their tools. It would work against our “laziness” instincts.
If an agent handles a big task, why should we split it into smaller ones and review them gradually one by one, again? Isn’t it more effective to have the whole thing run at once rather than stopping it each time it approaches 200 lines of code changes? (By the way, it isn’t, but that’s another discussion.)
Finally, we get the perceived efficiency gains right here, right now, while the cost of lower quality is deferred to the future. Sadly, sticking to the engineering practices that kept the quality high seems highly unlikely.
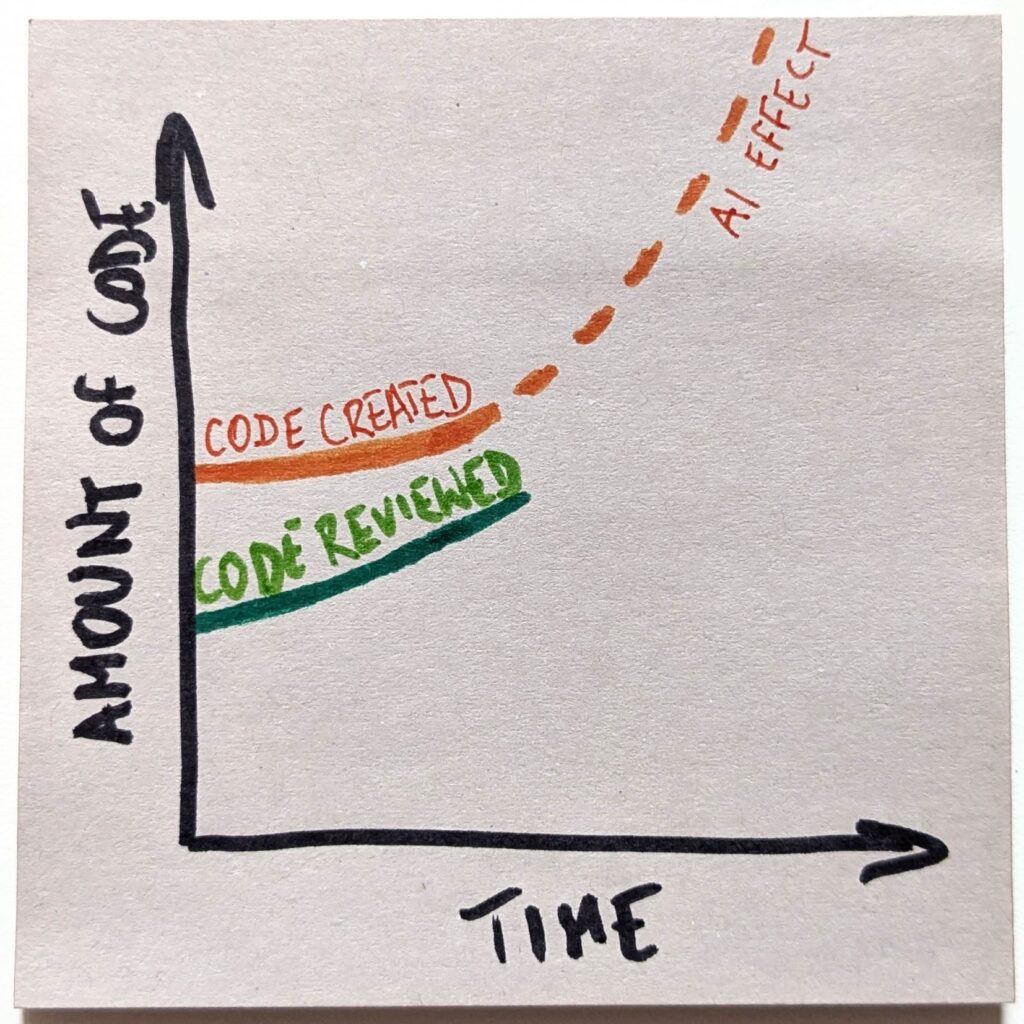
As the capabilities of the models allow them to handle larger and larger coding tasks, the typical pull request size will go up.
As a result, reviewers will overlook more and more defects.
The fact that reviewers don’t dive deeply into the code conceptually will only exacerbate the quality issue.
Thus, we will increasingly develop software riddled with defects.
Said defects will add rework for coding agents and humans alike.
The pace of delivery of value-adding items will necessarily slow down, as more effort goes into rework (and rework of rework).
We will go so much faster, only to go as slow as we did in the past. Or slower still. That is, assuming that we stick to the idea of the human reviewer in the loop. And that’s not granted.
For decades, we tried to learn to work in small batches. The hard way, let me add. Now, with AI, we’re making a U-turn as if none of it mattered. I have bad news. It still does. It was never a software-specific thing. In fact, we stole it from manufacturing in the first place.
We will relearn small batches. Sooner than we think.
I’m sorry. This is a rant. Which you’ve probably guessed by the title, duh!
The straw that broke my back was the lead I saw:
“Sweden built smart machines where crows trade trash for food, turning clever birds into unexpected city cleaners.”
A clearly AI-generated image didn’t help the credibility (a three-legged crow is quite telling), yet it’s the headline that made me do the search. “Search” is such a big word, though. It was literally one query.
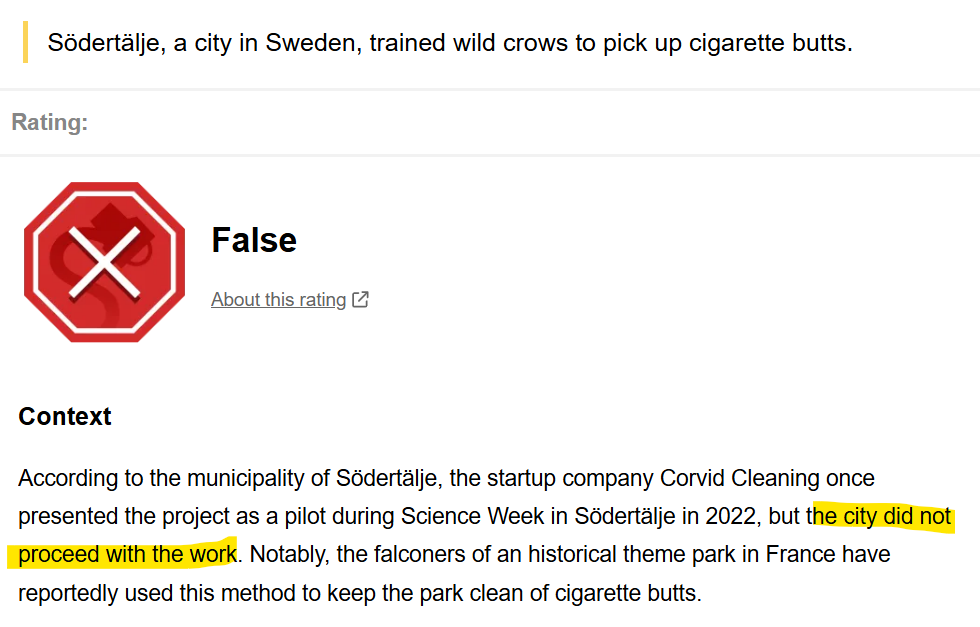
Not Sweden, but one Swedish startup. Not built, but run a one-time pilot. And it didn’t get anywhere close to turning crows into city cleaners as the project was abandoned with zero follow-up. Fact check here.
Yet it sure works as eye candy if you want to glue someone’s attention to your clearly AI-generated LinkedIn post that tries to sell something (I don’t know what exactly; I’m incentivized to stop reading once I see an AI-generated graphic).
Links No Longer Mean Credibility
Crow cleaners’ story, as amusing as it might have been, wouldn’t get me to write a post, though. In fact, fake references have been a pet peeve for quite some time already, so it was just “another one of these.”
Here’s a more interesting case. Recently, I read a story about AI in coding, full of data backing the author’s claims. One particular fact was the following:
“The SmartBear/Cisco study established numbers everyone ignores: defect detection drops from 87% for PRs under 100 lines to 28% for PRs over 1,000 lines.”
Cool. That’s something I’m researching right now. Let’s take a look at the study and see what I can learn from the data. Ops, the link doesn’t lead to the study, but to another article. But that article, in turn, has a link of its own. Which leads to yet another article that doesn’t even mention the study anymore.
By the way, neither of the websites in the link chain mentioned the numbers from the original quote. I bet they were AI-generated with no human validation whatsoever.
Even a mildly competent human would spot the inconsistency. And the author clearly aspires to a higher expertise league than just “mildly competent.”
Source Data Is the Usual Suspect for Hallucination
Now, the SmartBear/Cisco study is easily googlable, so ultimately the link chain was a minor nuisance. Reading the paper was, however, an enlightening experience.
There isn’t a single place in the research where it claims 87% or 28% detection rates for specific pull request sizes. Across the entire data sample, there are scarcely any data points with a PR size over 1,000 lines of code. Finally, the paper does not explicitly measure defect detection as an analyzed parameter (it uses defect density and draws some conclusions about detection rates).
In other words, the whole claim in the original article must have been hallucinated.
In the author’s defense, the SmartBear/Cisco study infers that longer PRs may lead to worse defect detection. But it makes the claim neither explicitly nor directly.
“Inspection rates less than 300 LOC/hour result in best defect detection. Rates under 500 are still good; expect to miss significant percentage of defects if faster than that.”
The angle is the number of lines reviewed per hour, not the PR size. The inference is that larger PRs take longer, and there was an observable tendency for reviewers to speed up the process when it takes more time. The pace of the review, in turn, is inversely correlated with the defect density.
That’s pretty far from “defect detection drops from 87% to 28%.”
AI Fails at the Fringes
That’s a perfect example of AI unreliability at the fringes. There isn’t a particularly huge data sample of “SmartBear/Cisco studies” or research showing specific code review dynamics. For an LLM, this already means the fringes.
If we run AI on autopilot, it will certainly deliver a result. In a likely case, when an LLM doesn’t find a relevant answer, it will hallucinate something. It will gladly make up the numbers. They will look fine. Specific. Sound. With a bit of luck, they may even be (somewhat) in line with what the source actually said. But will it actually be what the study reported?
Sadly, the more we outsource the data research to AI, the more spot-on my irony might be. And it will only get worse. The original piece with made-up numbers will soon be used by another LLM as a credible article. After all, it looks like one. The length of the link chain will go up by one, adding even more self-reinforcing noise to future AI queries. Good f**cking job, everyone!
Credibility Is Our Currency
OK, I know. I won’t turn the tide. AI slop is there to stay. Algorithms reward it. Writing a piece takes me around a couple of hours. More if I need to research background facts. Add some time for post-editing.
ChatGPT could have done that for me in minutes. While I’m sipping coffee and enjoying the sun. With plenty of outgoing links and a shitton of reference data. No sweat. And the result? Save for some personal vibe, it may look just as good as mine.
The only price to pay would be my credibility. The data pulled by an LLM might be misinterpreted (if I’m lucky) or entirely fake (if I’m not). The reference links would lead to whichever posts rank best at Generative Engine Optimization (which is SEO A.D. 2026). These pages, coincidentally, tend to be awful to read for a human. The end result would be something I wouldn’t consciously sign my name to.
I’d basically be my cheap, anonymous version of Elon Musk, passing a seemingly hilarious (also fake) joke about a major AWS outage.
With a shrinking attention span, we don’t want to spend time reading the actual research paper to back up our brainfart claim. I get it. I go through the pain myself.
5 years ago, we needed to be pretty precise with our Google-Fu to find a fitting research paper to back [insert any statement here]. Now? Explain that in plain English to ChatGPT or Gemini, and voila! Here’s a freshly baked link for you.
It’s probably shit, but how would you know? That is, unless you do your f**cking homework and read the thing for yourself. And then apply at least a minimum judgment.
I mean, as writers, we necessarily are readers, too. Making the data up is like shitting on your own doorstep. Why would you believe any stuff you read if you get AI to make the shit up in your “writing” unattended? Ultimately, why would you expect anyone to care more than you do?
So, be so kind and do check your f**cking sources, people!
I actually read the sources I link here. Including the SmartBear/Cisco study. I know, weird, right? 웃 https://okhuman.com/M0eKWQ
When I first stumbled upon Conway’s Law, it was anything but intuitive to me.
Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations. Melvin E. Conway
Why would an organizational structure of a company have anything to do with software architecture? After all, there are whole bodies of knowledge covering high- and low-level concepts of software development. Aren’t these things properly planned and executed?
I mean, sure, in the details, there will always be a mess. However, in a grand scheme of things, the high-level design should be far more controllable than the law suggests.
In retrospect, Conway’s Law is one of those things that, once you’ve seen it, you can’t unsee it.
Conway’s Law and Spotify Model
Whenever Conway’s Law emerges in a discussion, my favorite example is Spotify. I’m a user since the beta. I know several people who worked there in leadership positions. Most of all, Spotify, at some point, was very vocal about their organizational approach, the so-called Spotify Model. It’s like I have enough data to connect the dots.
As popular as it was at the time, if you look at the Spotify Model, it’s hard not to see it as a glorified matrix organization. Yes, there’s more autonomy across the board, but the communication paths? They all scream “Matrix!”
What should we expect from their product design if Conway’s Law is true? My best guess is a set of features interconnected in non-obvious ways, with a common issue of lack of alignment, and a lot of local optimizations. And that’s precisely what we get.
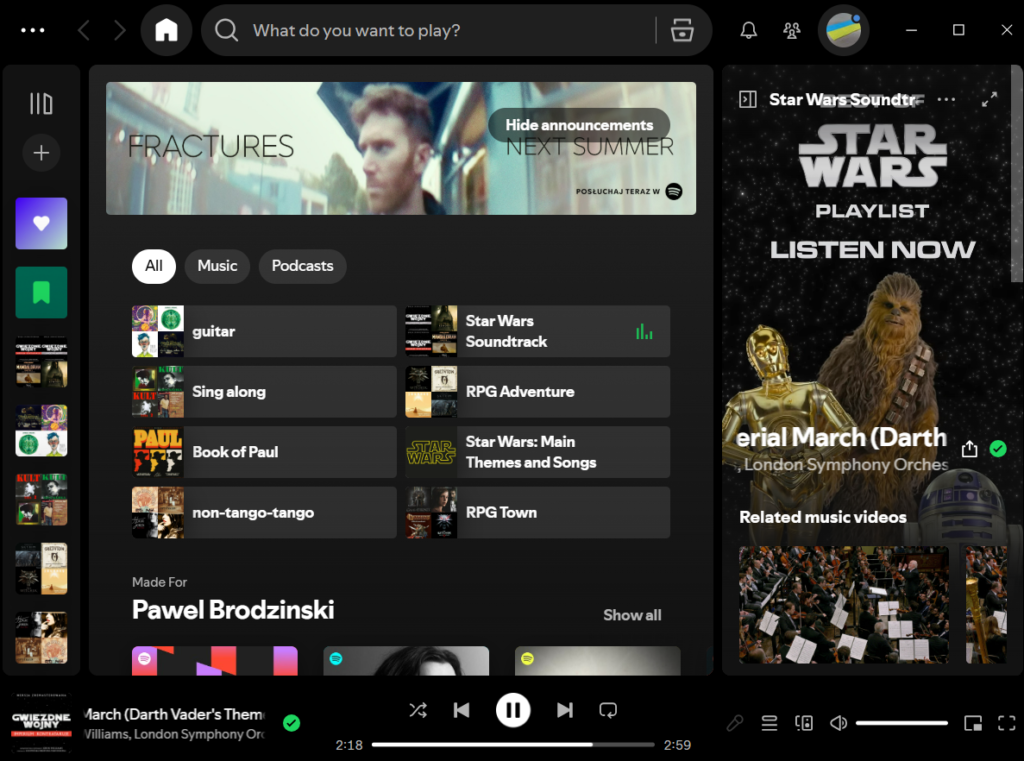
Spotify UX
While Spotify’s codebase is not open, its UX is quite telling. By now, it’s a clutterball of misaligned ideas fighting for your attention.
Playlist sidebar, announcements, recently played, made for me, music video, related music videos, now playing… Welcome to the Spotify home screen.
From a user perspective, it’s fascinating, although not in a good way, how I struggle to find the same options that I use regularly (like, multiple times a week, for years). Managing playlists? Oh, boy. Search? Every other time, it’s in the wrong context. Inconsistencies between mobile and web? Don’t get me started.
But maybe it’s just grumpy me. Fine. I’ve just literally googled “who loves spotify ux?” and among the top results are:
Doesn’t sound like a love wave, really. It’s either one: Google reads my mind, or the UX is problematic.
All that comes from a product praised (and copied) for some product innovations, such as Discovery Weekly or Spotify Wrapped. Most definitely, not everything is wrong here. It’s just a matrix of somewhat misaligned ideas, good and bad. That isn’t really a recipe for customer delight.
By the way, did you know that Spotify has a custom seek bar for Star Wars songs that looks like a lightsaber? And you can change the looks of the specific lightsabers, no less. There could hardly be a better illustration of “a matrix of somewhat misaligned ideas, good and bad.”
Communication, Alignment, Autonomy
If you consider Conway’s Law, it’s hard not to see how Spotify UX is a precise map for the Spotify Model. Wherever communication between teams (squads, guilds, chapters, or whatever the hell they call them) was messy and faced multiple conflicting goals, so did the interconnections between features.
To make things harder, Spotify sprinkled high autonomy over their feature teams. So the matrix organization made alignment a challenge, yet decision-making was pushed down the hierarchy nonetheless.
In the late 2010s, Spotify had a few dozen relatively independent feature teams responsible for specific parts of the product. Small wonder that the “mobile playlist” team had different ideas from the “web playlist” team. Communication paths that might have fixed that were watered down by an overly complex organizational model.
By now, the engineering headcount is already in the thousands, and the team count is thus in the hundreds. Just imagine the product mess that the Spotify Model would create. No wonder they largely abandoned it.
OK, but what does it have to do with AI?
AI Product Management
Product people are encouraged almost as strongly as developers to use AI extensively. It comes as a mixed blessing. Early intensive prototyping is a viable path, and it opens up whole new avenues for validating product desirability.
LLMs make it just so easy to create extensive specifications. We can attach all the existing product descriptions as context, let AI do its own research, analyze the codebase, and more. It will produce a nice, detailed description, and the engineers will nail it.
Except we misinterpret the ease of creation for the value of the output.
A sidenote: It’s the same aspiration we had when we tried to model systems with UML diagrams, and it didn’t work either. It’s not about the tools. It’s about the iterative exploratory nature of designing software.
Still, AI can create the same illusion we followed many times before—that we can specify software upfront in detail from the outset. The output looks good. Better than ever, even. And we get it effortlessly. It’s the AI model that does the heavy lifting.
It takes some time to realize that product development doesn’t work like this. It never has. And it has nothing to do with the tools we use to create specs.
AI Kills Communication
In the past, product specifications were brief. Save maybe for some Business Analysts, no one fancied writing long forms describing all the feature details. We relied on just enough context and communication between engineers and product people.
However, now, generating detailed specifications with AI is easy and cheap. Initially, we might even verify whether the output is correct. Eventually, we’ll give up. One, often they’d be good enough. Two, LLMs are great at creating outputs that sound sensible. Three, honestly, read a 4-pager with a feature description and tell me you understood everything.
At some point, and sooner rather than later, a product manager will stop carefully verifying AI output. Soon, the developers will follow. That is, given they read the extensive specs at all in the first place. It quickly evolves into the “you give me the specs, I’ll get them built, no questions asked” kind of scenario.
The key part here is: “no questions asked.” It’s like going all the way back to the 90s, way before Agile happened. We build up to the specs, whether it makes sense or not. The only difference is that we deal with the development so much faster. Does it matter, though, when we build the wrong thing?
Conway’s Law Meets AI Product Management
The most important change happened in between the lines, though. A one-sentence-long feature description was, by definition, full of holes and required the team to discuss. A detailed specification creates the illusion that a feature has been thought through from all angles.
The former invites communication. The latter discourages it.
As we close down communication paths, Conway’s Law kicks in. We’re bound to design architectures that copy organizational communication structures.
Less peer-to-peer communication and less collaborative exploration mean a more fragmented and less coherent architecture. As each individual is treated more and more as an isolated island, so will be the code that individual develops.
The effect will affect both a technical level (think code architecture) and a product level (think UX). Give such a way of working a couple of years, and we’ll start praising Spotify for its exceptional product design in comparison.
AI Is on a Collision Course with Conway’s Law
Dev: The last feature is on staging. PM [checks the feature out]: It doesn’t work as specified! Here’s what should be different. Dev [checks the code, checks the specs, 2 hours have passed]: Well, actually, it works as specified. Here are the specific parts that prove my point. PM: Oh, my Claude must have hallucinated that part.
That’s an actual conversation that I heard that inspired this article. When I consider the impact of AI on communication, the paths connecting product and engineering are most affected. Yet, similar effects emerge across the board.
A single developer may produce more code with AI tools, so they are more independent and, even under time pressure, they don’t need to collaborate with other engineers as often. We reduce the need for communication.
Coding agents running independently step on each other’s toes way more carelessly, creating merge conflicts and triggering rework (the worst kind of rework, actually). Operators of said agents are thus better off when they isolate their active work areas. Which means less coordination and less communication.
The asynchronous nature of working with AI agents incentivizes the “throw over the fence” hand-offs. My agent’s output may be ready when I’m already off, but let that not stop you from doing whatever you need to do with it. Again, less human-to-human communication.
The sheer amount of documentation we can generate on different levels automates away collaborative activities (or parts of them). Code review? Let an agent handle that. Even less communication, perchance?
If Conway’s Law holds, we may be up for a rude awakening. As an industry, we are hyped about all sorts of “my agent talks to your agent” scenarios. It’s easy to see the upside—automating away the mundane, tedious, and routine. It’s hard to see the long-term cost of deteriorating communication paths.
So, we either learn to navigate the new realities of collaboration better, or we accept that the products we use will increasingly be crap. Which one will it be?
The last couple of years have been riddled with speculations about how AI will change the world. Software development and the broader IT industry are among the most affected contexts. Things are changing. The future is uncertain.
In such a landscape, it’s easy to subscribe to any speculation, like the infamous doom and gloom Citrini prediction. Before we fall for that, though, let’s look at the historical data.
It’s Q2 2026. If the AI predictions had been correct, then:
Why would they? After all, no one learns to code these days, because “everybody is now a programmer.”Courtesy of Jensen Huang.
If you want concrete data, since last autumn, AI writes 90% of the code. Yup, that’s Dario Amodei.
No one drops a tear over developers, though, because we already see how AI is in the midst of wiping out half of entry-level white-collar jobs. That’s Dario Amodei, too.
Yeah, I get your skepticism. That’s not reality I see around either. Fear not, however. Software engineers will go extinct this year. This time for real, says Dario Amodei. This time, we can trust him. For sure. Probably. Maybe.
Each time such an alarmistic prediction emerges, I ask one question: If X is true, what does the endgame look like?
What Is the Endgame?
I borrowed the idea of endgame from gaming, duh! Some gaming genres are built around a character progression. However, when a player character reaches the maximum level, the original game engine ceases to work. There’s no more level to grind. No more progression to make.
Thus, the endgame content was born. These are parts of a game designed specifically for max-level characters to keep the players interested. Typically, these are increasingly challenging. This time, the goal is not progress, but mastery. It’s like a game in a game.
The endgame content responds to the question of a hypothetical newbie player: “What happens if I play this game and keep progressing with my character?”
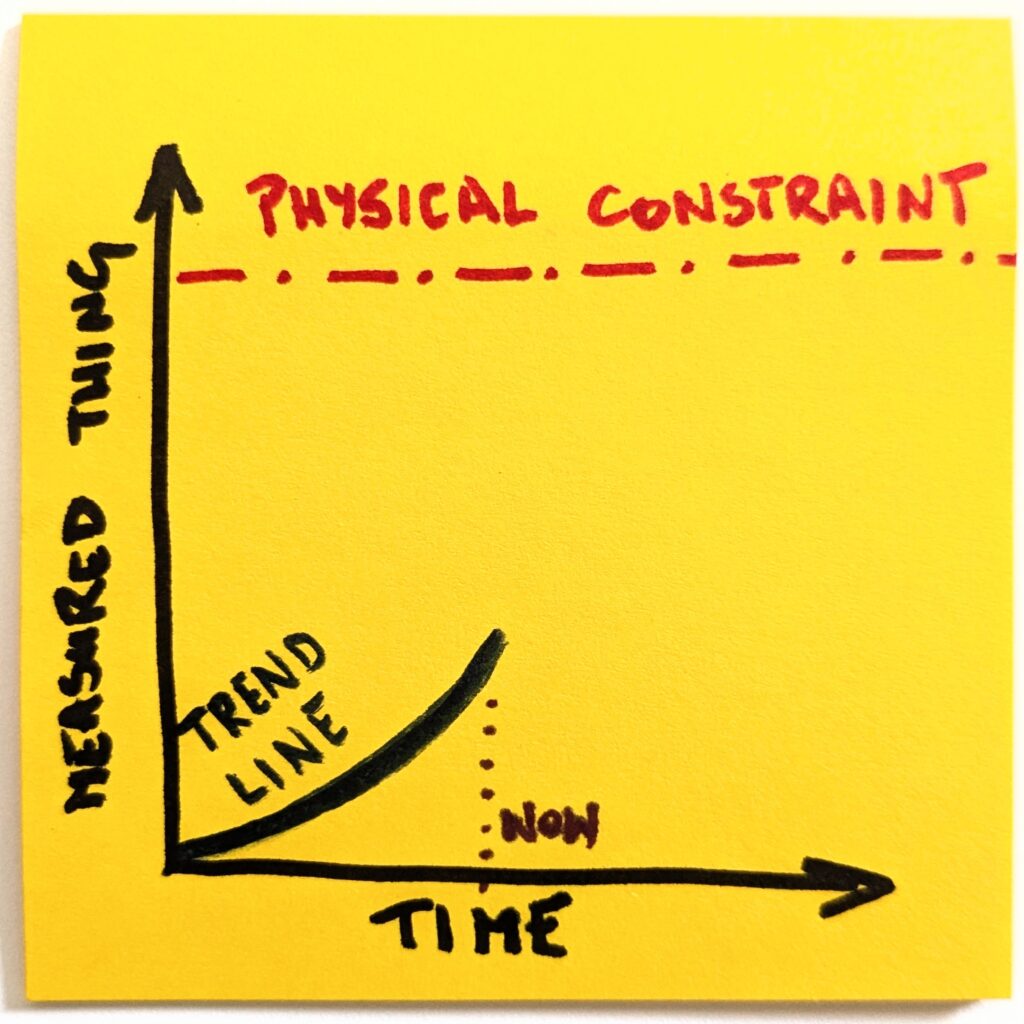
The question is interesting because we can envision the progression and intuitively realize that it can’t last indefinitely. At some point, an external constraint would impose itself, and our linear approximation of the trend (leveling up in this case) would break.
Thus, the question: What does the endgame look like?
The Endgame Question Is More Than Relevant in Business
If we look at market trends, the dynamics are surprisingly analogous. It’s not a game, so we don’t control the trends, but they’re there, sure enough. And they can’t last indefinitely. There’s always an external constraint that will impose itself.
The market share can’t go higher than 100%. The exponential growth can’t last more than a few years. Businesses need to make a profit eventually. And so on.
Now, if we ask the right questions, we don’t need to wait for the change to happen to see how the landscape will evolve. Better yet, we might see other facets of the change. Think of it as ripple effects. Then, suddenly, the landscape is richer, and we may come to very different conclusions from those we’d make if we looked at a trend in isolation.
A good example is what’s been dubbed a SaaSpocalypse—a recent devaluation of many SaaS businesses. What some perceived as the new trend predicting the end of SaaS, I consider merely a regression to the mean.
If this trend continued, the purchase price of these “old-school” product companies would be a bargain. They have healthy financials. Some have just recorded the best year ever. Unlike some of the tech scene darlings, they’re making actual profits. Plenty of them. Fundamentally, little has changed for these companies short- and mid-term.
It’s then relatively easy to see the endgame. The trend won’t continue too far, as eventually it would mean buying a dollar for fifty cents.
The Interconnected Trends and Second-Order Consequences
The endgame question is even more interesting whenever there’s no obvious limiting condition (like “you can’t have more than 100% of market share”). A good example is how AI affects coding.
We see increasing AI use in code generation. It’s not anywhere close to 90%, sure, but no one challenges that we’re doing more of that. Also, it’s obvious that AI agents can generate tons of code. And then some. No sweat.
The trend, then, suggests that we will have more and more of AI-generated code. Let’s then draw the trend line to the future and ask: What does the endgame look like?
Given how increasingly useful AI tools are, there’s no stopping the trend. At this pace, we will soon generate more code than we can reasonably review as we go. Once we stop the just-in-time code review, we will lose comprehension of what’s at the code level in our products.
These are second- or third-order consequences of code-generation capabilities we have thanks to AI tools. And these are precisely the considerations that any product business should take into account these days.
These are far more interesting than boasting about how much code is AI-generated. As a customer, I couldn’t care less whether you generate 30% of your code. Or 90%. Or none at all. I do care whether the product solves my problem now and whether it will be technically sustainable in a year from now.
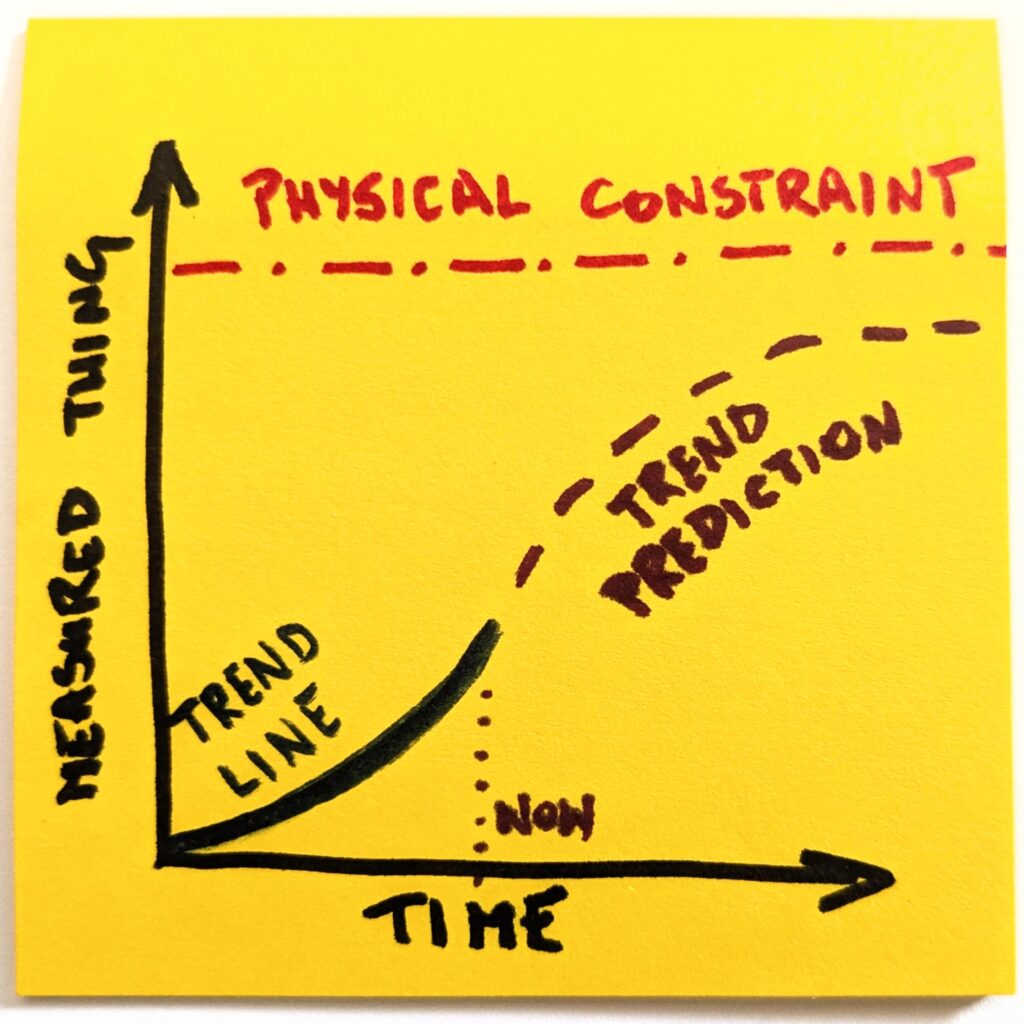
The reason why the endgame question is so powerful is that it skips the current condition and jumps directly to the future state:
What will be new or different once this new thing becomes the norm?
When does the trend become unsustainable?
How do correlated trends behave?
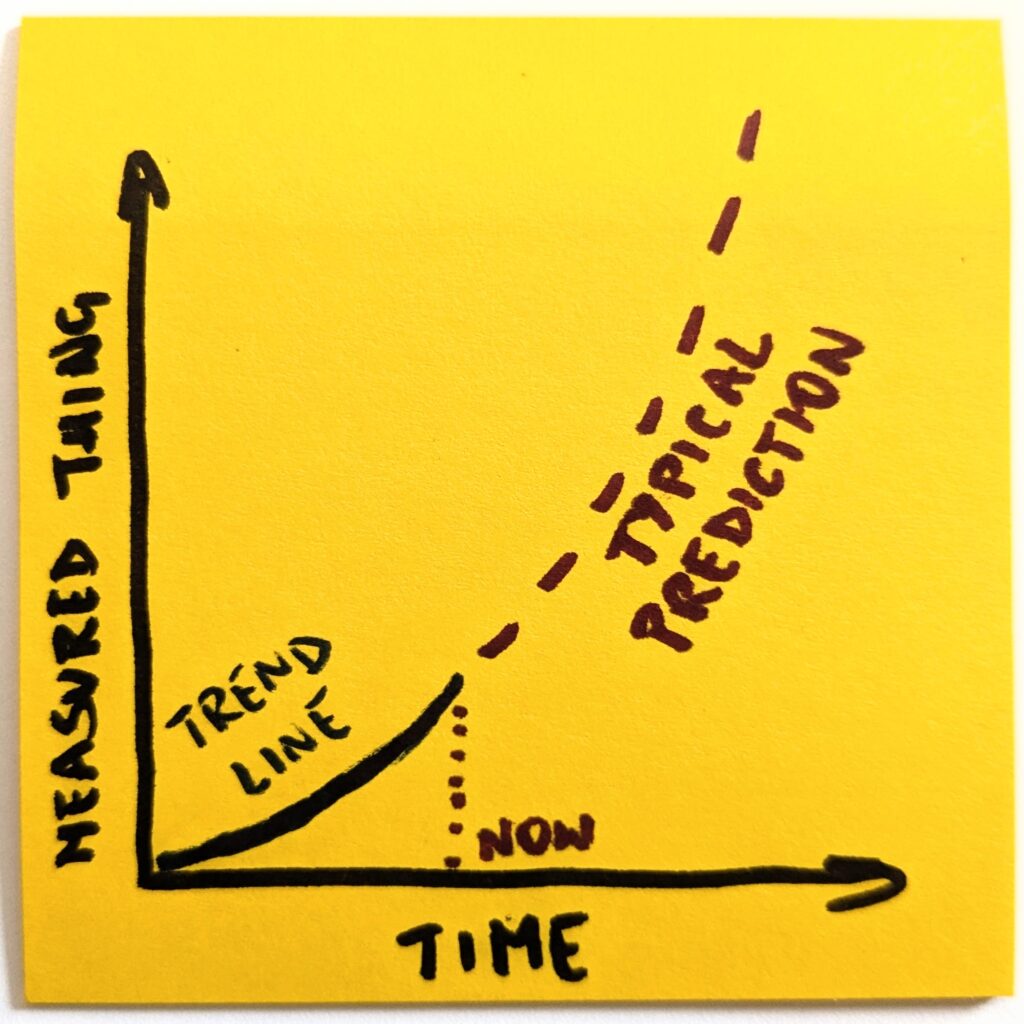
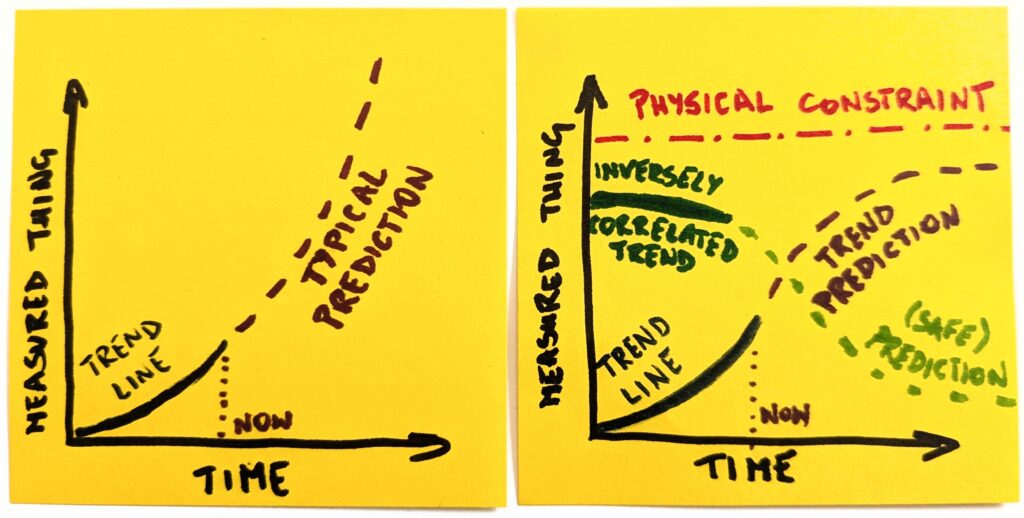
Think of it as a model. We look at one thing and have historical data on how it has behaved so far. Now, the simplest possible thing is to extend the trend line indefinitely into the future.
Except, as we already established, things do not work like this. In no reality does OpenAI have 8 billion paying ChatGPT users. So, before we predict the future, we consider external constraints.
Once we make it explicit, it becomes obvious that a naive version of the future will not happen. Even if we assume the most optimistic scenarios, the trend line will have to change its shape.
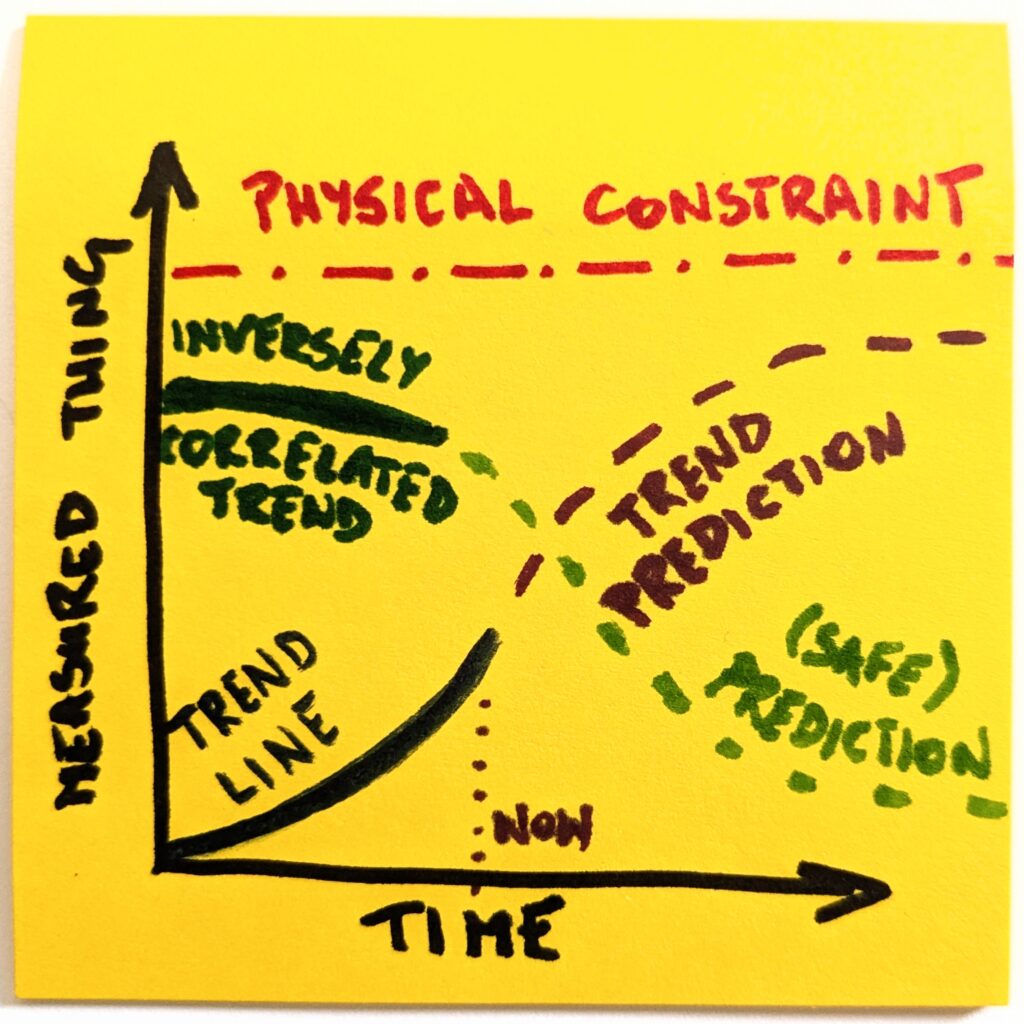
Well, that’s different now, thank you. But we’re not done yet. The most interesting things happen at the intersection. We can ask ourselves which other trends are correlated with whatever we focus on.
Like, if there’s more of this, there should also be more of that. Or vice versa, if there’s more of this, there should be less of that. As with our example, if we generate more and more code, there will necessarily be less technical comprehension. The stronger one is, the weaker the other will become.
Since we already have a clearer picture of the landscape, it’s not that hard to predict how an inversely correlated thing will change. And to what degree. Suddenly, we are equipped to ask questions about second-order consequences.
That’s where the endgame question shines. Instead of boasting about which big tech generates more code or predicting when developers go extinct, we may consider possible futures.
Human in the Loop and Coding
To run a quick example I touched on earlier, let’s consider AI and coding. Dario Amodei is wrong about how fast his AI models will take over coding. But it’s not because of the lack of capabilities of said models. I mean that too, but he knows more about these capabilities than you or me, and maybe he has all the right to believe it’s a technical problem that’s going to be fixed eventually.
He’s wrong because he considers code generation in a surprisingly isolated sandbox. If we were to believe Amodei’s predictions, we would have to assume that human-in-the-loop will be gone from software engineering.
I mean, physically, we can keep humans there, but they will have no real role. They’d be overloaded and incapable of good judgment. In fact, it’s already happening. Speculatively, though likely, in recent wars, humans-in-the-loop had the final call with decisions about strikes. Yet, you can’t expect good judgment if someone is expected to make 80 life-or-death decisions per hour.
There might still be a human body in the loop. The judgment, though? With enough cognitive load, it’s gone.
Just compare these two predictions. The first is a naive one, and considers a thing in isolation. The second attempts to understand what would change and how if the current trends stay with us. These two look very different.
The Endgame Question for Coding
So let’s look at what answers the endgame question yields in the coding example. In the past decades, we’ve been creating a growing amount of code. And yet, code review as a practice has also been increasingly popular.
AI has introduced a foreign element to our system. Now we can easily generate as much code as we want. Increasingly, we do. That changes the current dynamics of software development trends.
But wait, so far, the “code review” trend has been all good. The practice has been growing in popularity, despite the fact that, as a whole, we were developing more code.
Hell, one way of looking at it is that all code has been reviewed, since the developer creating it was doing a sort of review as part of the creative process.
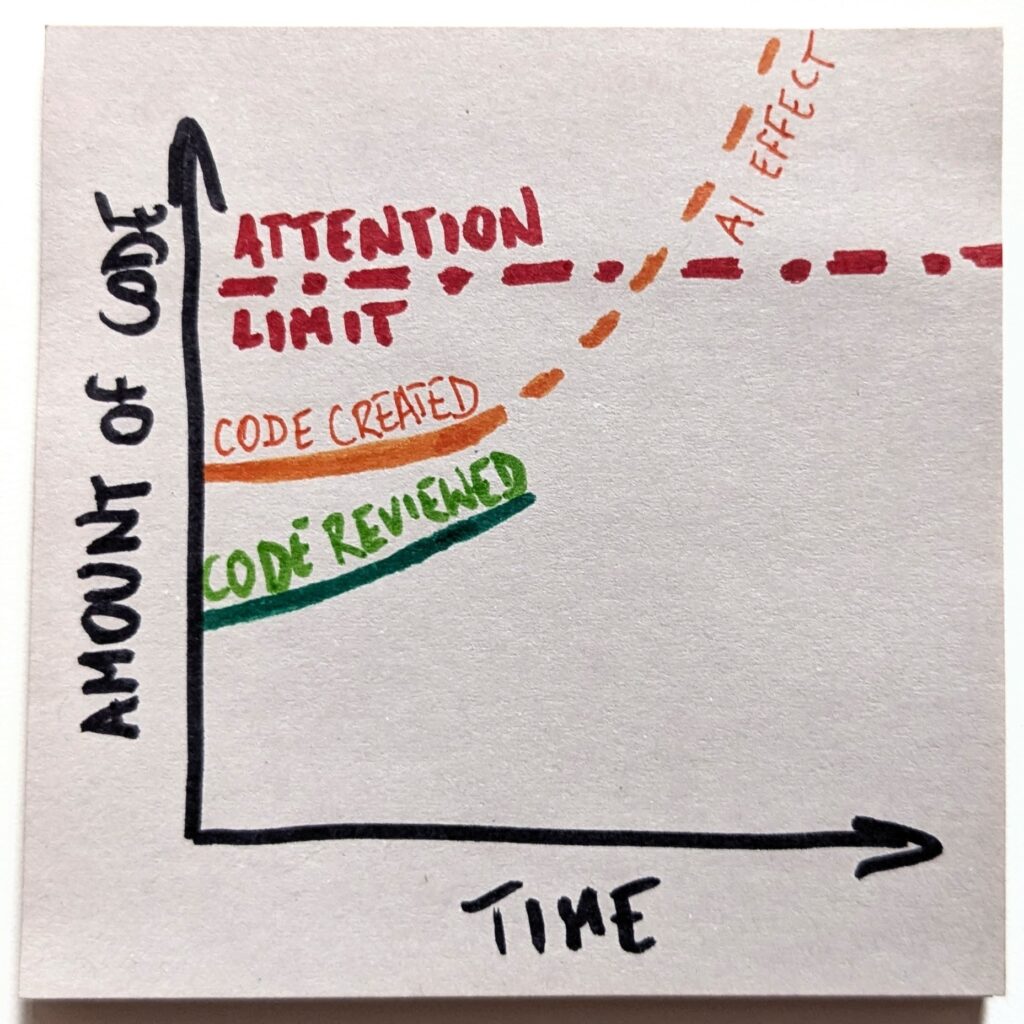
The only problem is that code review is a cognitive task that requires attention. And we have a limited pool of it. If we suddenly needed to review 10x as much code, we don’t have enough engineers to handle that.
Even if we try to keep up, which I call an “optimistic” scenario here, we eventually hit the ceiling. There’s no more available attention to pay.
A side note: we could argue that we actually raise the limit by freeing developers from writing code, so they have more time to review it. That’s fair. However, we also claim we don’t need no new developers (so we don’t train them) and lay them off (so they change industries). Effectively, we’re working the limit line in both directions. In either case, even if it goes somewhat up, we’ll cross it soon enough.
With that, we’ll create a gap between the amount of code we create and the loads we are capable of reviewing. And that gap will only keep growing. Fast.
That, in turn, is the exact reason the “optimistic” scenario will not happen. Playing a losing game is no fun. Even less so if that’s an increasingly losing game. The only sensible expectation is that we will stop playing the game altogether.
The new reality doesn’t mean stopping the reviews entirely. But we’ll need to pick our battles. And we’ll need to be increasingly picky about picking them. We’ll choose only the most critical parts of the code and maintain active knowledge of them.
Second-Order Consequences of the Coding Endgame
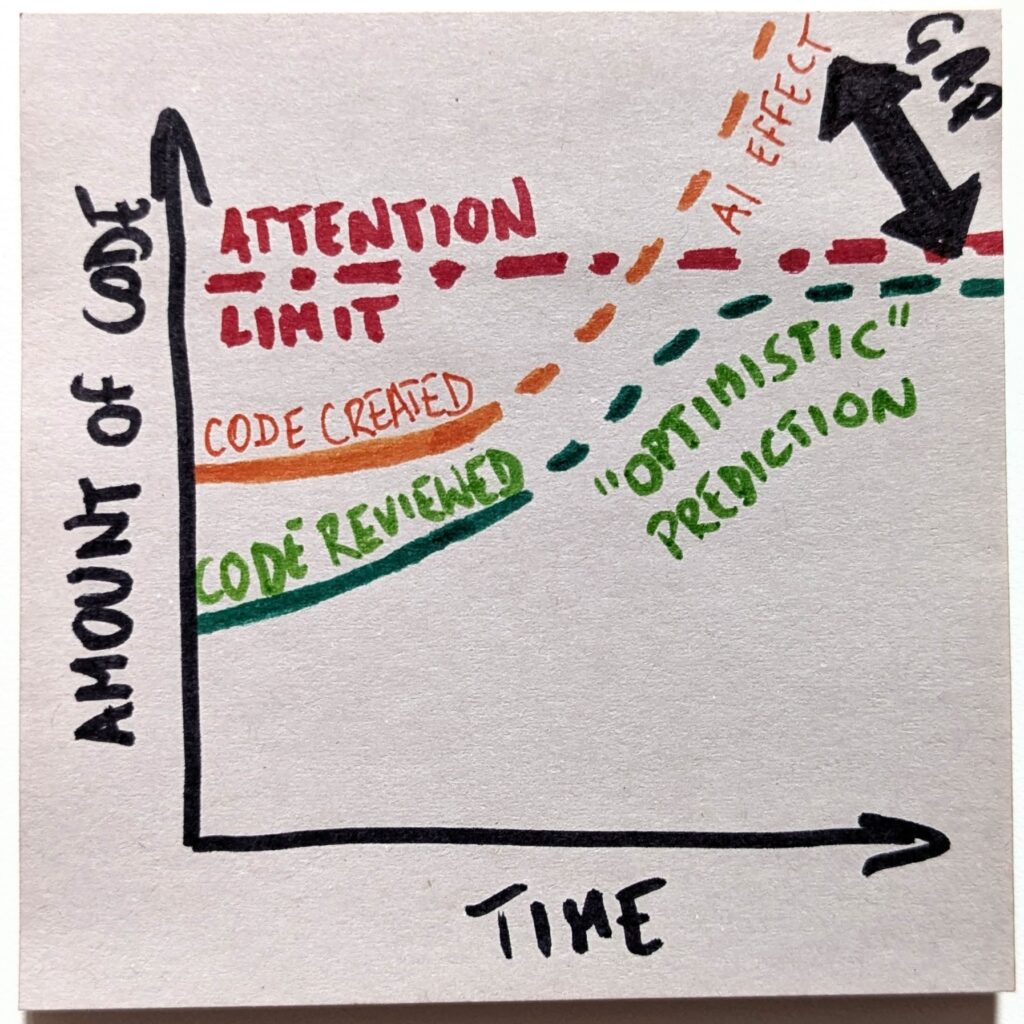
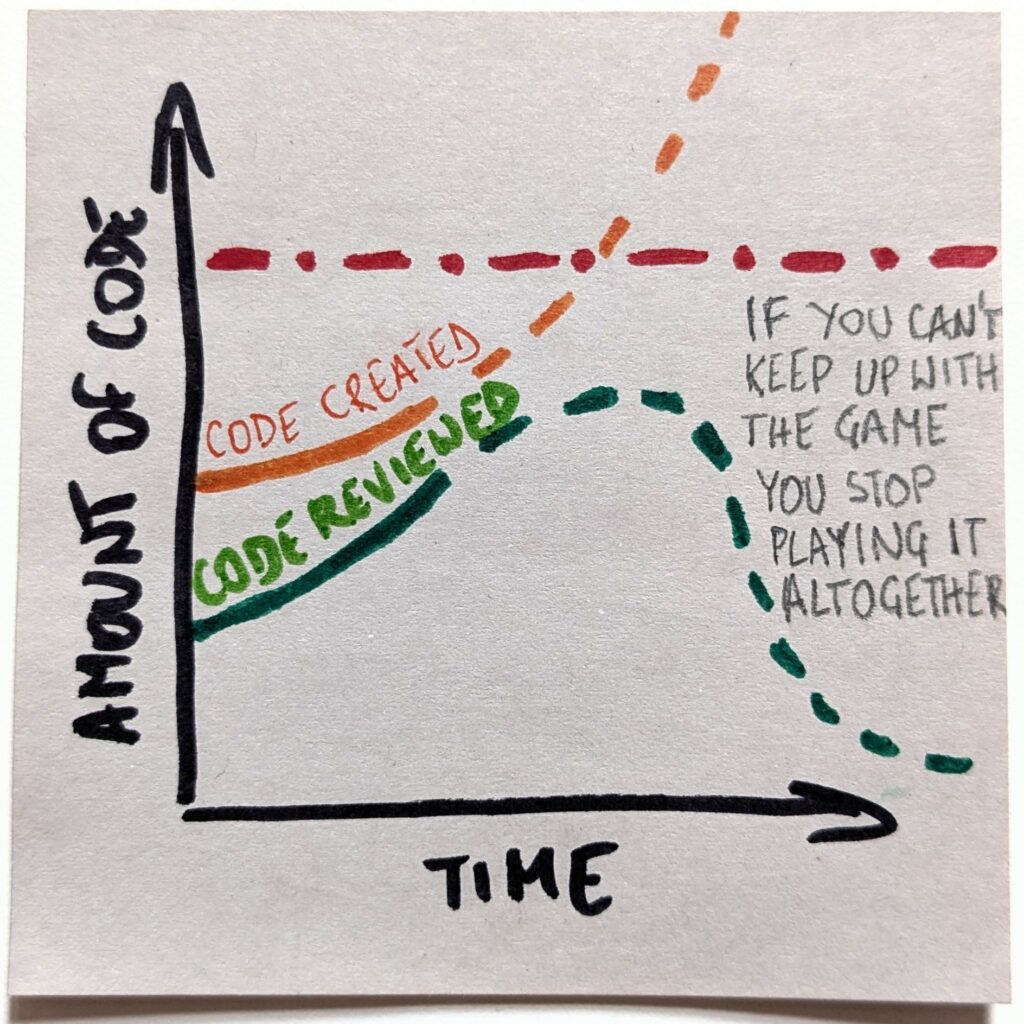
Things get even more interesting when we consider ripple effects. Before AI, basically, all the code was read. I mean, a human wrote it, so part of the process was looking at the thing. The “code read” curve was identical to the “code created” one.
However, as we stop writing code ourselves and expect the code review rate to nosedive, we’ll look at a completely different reality. “Code read” line will detach from “code created” and will follow “code reviewed.”
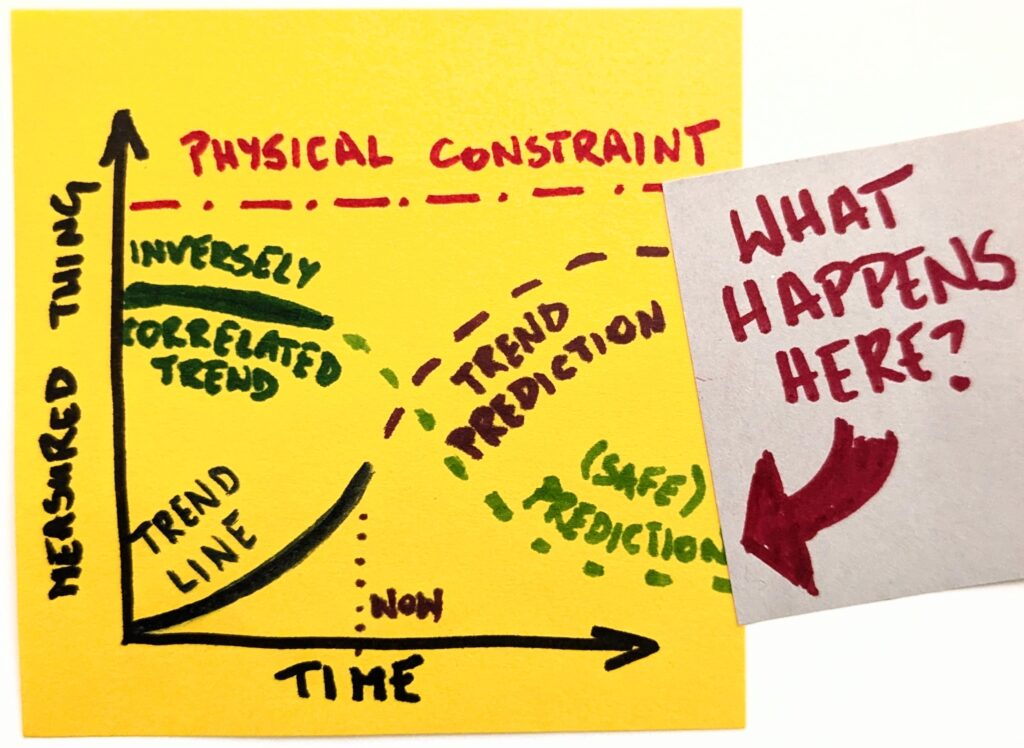
Now, that’s interesting. There is more code, but save for very few carefully chosen code bases, we neither read nor understand it. It’s as if there were islands of comprehension in a black-box ocean. That is, unless we fundamentally change something. So, are we ready to run critical systems on software we can’t comprehend? Because that’s what the endgame looks like.
And that’s but one example why the endgame question is such a neat trick. The moment we start asking it, we start seeing scenarios that go way beyond the hype. It’s not just “Claude Code is so awesome; it can do the coding for me.” It’s “Would I trust a vibe-coded e-commerce with my credit card number?” Or even “How would I feel if Visa or MasterCard ran on software no human comprehends?”
The Ultimate Question
Now, I know I rode the example of AI in coding in this post. The applicability of the endgame question is way broader, though. It literally pops up anytime someone makes a kind of bold prediction, well, about anything. You know, the type of “AI is capable of erasing half of white-collar jobs, so AI labs will get unfathomably rich,” or something along the same lines.
What does the endgame look like? Well, we make half of the knowledge workers unemployed, and who’s paying the AI bills, again?
Or take this: “AI will take over content generation as it can create 100x times as much as humans can, no sweat.” What does the endgame look like? We don’t have 100x as much attention, so the vast majority of the generated content will not be consumed at all. We may have the effect of bad money driving out good, but we won’t fundamentally have use of more content.
“Thanks to AI capabilities, we’ll see a surge of new products. Anyone will be able to run a product now.” What does the endgame look like? Again, the attention constraint (or the demography) suggests we won’t have 100x as many customers. So, if anything, we’ll just increase the failure rate. While running a startup is already unappealing, it will become even less of a winning proposition, which will actively drive people away from that path.
“AI will automate applying for jobs.” What does the endgame look like? Both sides get automated to handle an increasing load. Eventually, it’s one AI agent negotiating with another to figure out whether a human is a good fit for an organization. The system is bound to be misaligned and thus gamed. What follows is that we’ll either accept hiring candidates who are increasingly unfit for the role (but who played the game better) or reinvent the hiring system altogether.
So before we jump on another bit of “CEO said a thing” journalism, it’s worth asking: if that’s true, what does the endgame look like?
As hilarious as it would be, given the topic, this post has not been AI-generated. 웃 https://okhuman.com/wLBTwg
As a job applicant, would you pay to make sure someone reads your application?
Here’s a sad reality for many people applying for a job:
Their competitors (i.e., other candidates) use AI tools to mass apply.
As a result, hiring companies are flooded with applications, and sifting through all of them is impractical.
What follows is that hiring companies defer to other AI tools to filter out the vast majority of applications (often as much as 95%+).
The recruitment game becomes one of prompting one AI agent to pass through the filters of another AI agent.
Realities of Job Seekers A.D. 2025
Imagine that there is a job that you really want to get. It doesn’t even matter why. It may be because you know that the company is great, or the job profile matches your dreams perfectly, or you perceive the experience you’d get there as unique, or whatever. You just want in.
But hey, since all those other people are using AI tools to spam the hiring company’s application form, your submission will disappear in that flood.
It’s even worse than that. If you hand-craft your application to show your genuine care for the job, it’s almost certain that you’ll be rejected. After all, your original story will be written to a hiring manager (a human), but it’s never going to get there in the first place. It will be rejected by an automated AI tool (a bot) precisely because it’s non-conformist.
Such a resume doesn’t match the most common patterns. There aren’t many similar examples in the AI model’s training data. It’s not common enough.
If you want your application to get past the AI filter, you kinda have to play the game everyone else does. Optimize for what a bot wants. And it’s impractical to do it by hand. Just hire another AI agent to do it for you.
Except that you’ve defeated the purpose that way. First, you aren’t more likely to get through. Second, even in the case that you do, the hiring manager will see another similar, bland-but-professional resume. You will not stand out.
Most importantly, you will not carry over your care about that job.
You can pretend it’s 2020 and send your manually-crafted CV, but you’re going to lose to people auto-submitting thousands of AI-generated resumes. Oh, and said resumes will be automatically tweaked to better match a job description, with no human effort whatsoever.
A resume doesn’t work as a token of information exchanged between two humans (a hiring manager and a candidate) anymore.
The career of a resume is over. At least the one that we know. If anything, a CV becomes a token exchanged between two AI agents, neither of which is programmed by the actual candidate.
No matter how hard we try, there’s no coming back. We can’t make resumes unbroken again. Even if we aspirationally tried to restore the original meaning of a CV, there will always be a rogue player who will exploit that trust by mass-applying with generated stuff. And since that will give them a short-term advantage, others will follow suit.
Winning the Game by Not Playing It Altogether
It’s ironic how both sides of this equation—recruiters and candidates alike—are losing in the new setup. Candidates have it harder to show their care about specific jobs. Companies give up on the best matches because they employ a bot to reject 95% of applicants. And yet, no one can change the rules anymore.
So, is conforming to the new state of things the only option?
Image from the WarGames movie
In the classic movie WarGames, the AI, which is trying to “win” the nuclear war, eventually learns that it always ends in mutual assured destruction. The only winning move, thus, is not to play at all.
It’s the same with recruitment. If the current system forces us to mass-produce thousands and thousands of resumes that no one will ever read, we’re just adding noise to the system. The winning move? Not to play.
But wait, if you want to change jobs, how are you supposed not to play the game? If you never apply, you never get that dream job of yours. Or a better one than you have now.
Trust Networks as Antidote to AI Slop
In recruitment, as much as in any other area, we will defer to trust networks to circumvent the noise. The more toxic AI slop is in the feed, the less we trust the feed altogether, and the more we rely on human-to-human connections.
One side of relying on trust networks is that companies increasingly go for employee referrals rather than traditional open recruitment processes. That doesn’t solve the other part of the equation, though. What if I am a candidate and want that specific job?
Do the same. Build a connection with someone at that company. We live in an interconnected world, and there are still places where a genuine message will stand out. They may attend local meetups, be active on LinkedIn, maybe publish a blog or a Substack, or engage in some other professional activities. If you care, you will figure that out. Get to know people first, and only then apply.
Does it seem like a lot of effort? That’s precisely the point. It shows how much you care.
Very recently, we made our first hire in almost two years. We didn’t even open a recruitment process. There was this guy who stayed in contact after we talked a few years back. And then, eventually, it was a good time for him and a good time for us. A win-win.
The point is: he made the effort to reconnect. He made it easy for us to remember.
This could only happen because we’ve built the human connection beforehand. We were two parts of the same trust network.
Would You Pay To Put Your Resume at a Hiring Manager’s Desk?
I admit, relying on trust networks is a lot of effort. And it takes time. Both would make the approach impractical at times. So what if there were a shortcut?
That brings me back to my original question. As a candidate applying for a job, would you pay to skip the AI line? Would you pay to ensure that your application is read by a human?
Note, your resume would still go through regular scrutiny. It’s just you’d know a human would do it, not a black-box AI agent.
There’s an interesting balance here. Make it too cheap, say $0.02, and it changes nothing. People would still be mass-applying all the same, so no one would take that seriously. Make it too expensive, say $200, and it’s probably not a good return on investment for a candidate. After all, no one would hire such a candidate or even rate them any better. A hiring manager would just read and assess the resume as if it passed the AI filters.
What’s in it for a candidate? It’s an open avenue to show genuine care. Since the applicant knows they’re not going through AI, they are free to optimize their application for a human reader. Hell, they actually are encouraged to go the extra mile with their application.
What’s in it for a hiring company? I reckon it wouldn’t make sense for a candidate to pay for mass applying, so they’d do that only for jobs they actually care about. So the hiring company gets a token of care along with a resume. Recruiters can still assess skills the way they do, but before committing any effort in interviews, they clearly know which candidates consider the position a great match.
So, would you pay to guarantee your resume is reviewed by a hiring manager? If so, how much?
Here’s a little experiment that’s in the spirit of the post. This link here is a token of human effort behind the post. 웃https://okhuman.com/CuC1uw
That is, “funny” as long as you’re not a customer of said services trying to do something important to you. I know how frustrating it was when Grammarly stopped correcting my writing during the outage, even if it’s anything but a critical service to me.
While AWS engineers were busy trying to get the services back online, the internet was busy mocking Amazon. Elon Musk’s tweet got turbo-popular, quickly getting several million pageviews and sparking buzz from Reddit to serious pundits.
Admittedly, it was spot on. No wonder it spread like wildfire. I got it as a meme, like an hour later, from a colleague. It would fit well with some of my snarky comments about AI, wouldn’t it?
However, before joining the mocking crowd, I tried to look up the source.
Don’t Trust Random Tweets
Finding the article used as a screenshot was easy enough. It was a CNBC piece on Matt Garman. Except the title didn’t say anything about how much AI-generated code AWS pushes to production.
Fair enough. Media are known to A/B test their titles to see which gets the most clicks. So I read the article, hoping to find a relevant reference. Nope. Nothing. Nil.
The article, as the title clearly suggests, is about something completely different.
I tried to google up the exact phrase. It returned only a Redit/X trail of the original “You don’t say” retort. Googling exact quotes from the CNBC article did return several links that republished the piece, but all used the original title, not the one from the smartass comment. It didn’t seem CNBC had been A/B testing the headline.
By that point, I was like, compare these two pictures. Find five differences (the bottom one is the legitimate screenshot).
Top picture from the tweet Elon Musk shared. Bottom from the actual CNBC article.
So yes, jokes on you, jokers.
Except no one cares, really. Everyone laughed, and few, if anyone, cared to check the source. Few, if anyone, cared to utter “sorry.”
Trustworthiness as the New Currency
I received Musk’s tweet as a meme from my colleagues. It went through at least two of them before landing in my Slack channel. They passed it with good intent. I mean, why would you double-check a screenshot from an article?
It’s a friggin’ screenshot, after all.
Except it’s not.
This story showcases the challenge we’re facing in the AI era. We have to raise our guard regarding what we trust. We increasingly have to assume that whatever we receive is not genuine.
It may be a meme, and we’ll have a laugh and move on. Whatever. It won’t hurt Matt Garman’s bonus. It won’t have a dent in Elon Musk’s trustworthiness (even if there were such a thing).
It may be a resume, though. A business offer. A networking invitation, recommendation, technical article, website, etc. It’s just so easy to generate any of these.
Well, if you know me, I probably didn’t need to ask you for a leap of faith in the originality of my writing. The reason is trustworthiness. That’s the currency we exchange here. You trust I wouldn’t throw AI slop at you.
If you landed here from a random place on the internet, well, you can’t know. That is, unless you got here via a share from someone whom you trust (at least a bit) and you extend the courtesy.
Trust in Business Dealings
The same pattern works in any professional situation. And, sadly, it is as much affected by the AI-generated flood as blogs/newsletters/articles.
When a company receives an application for an open position, it can’t know whether a candidate even applied for the job. It might have been an AI agent working on behalf of someone mass-applying to thousands of companies.
A way out? If someone you know (or someone known by someone you know) applies, you kinda trust it’s genuine. You will trust not only the act of applying but, most likely, extend it to the candidate’s self-assessment.
Trust is a universal hack to work around the flood of AI slop.
Outreach in a professional context? Same story. Cold outreach was broken before LLMs, but now we almost have to assume that it’s all AI agents hunting for gullible. But if someone you know made the connection, you’d listen.
Networking? Same thing. You can’t know whether a comment, post, or networking request was written by a human or a bot. OK, sometimes it’s almost obvious, but there’s a huge gray zone. In someone you trust does the intro, though? A different game.
The pattern is the same. Trust is like an antidote to all those things broken by AI slop.
Don’t We Care About Quality?
Let me get back to the stuff we read online for a moment. One argument that pops up in this context is that all we should care about is quality. It’s either good enough or not. If it is, why should we care who or what wrote it?
Fair enough. As long as consuming a bit of content is all we care about.
If I consider interacting with content in any way, it’s a different game.
With AI capabilities, we can generate almost infinitely more writing, art, music, etc. than what humans create. Some of it will be good enough, sure. I mean, ultimately, most of what humans create is mediocre, too. The bar is not that high.
There’s only one problem. We might have more stuff to consume, but we don’t have any more attention than we had.
Now, the big question. Would you rather interact with a human or a bot? If the former, then you may want to optimize the choice of what you consume accordingly.
Relying solely on what we personally trust would be impractical. There are only so many people I have met and learned to trust to a reasonable degree.
Limiting my options to hiring only among them, reading only what they create, doing business only with them, etc., would be plain stupid. So how do we balance our necessarily limited trust circle with the realities of untrustworthiness boosted by AI capabilities?
Elementary. Trust networks.
If I trust Jose, and Jose trusts Martin, then I extend my trust to Martin. If our connection works and I learn that Martin trusts James, then I trust James, too. And then I extend that to James’ acquaintances, as well. And yes, that’s an actual trust chain that worked for me.
By the same token, if you trust me with my writing, you can assume that I don’t link shit in my posts. Sure, I won’t guarantee that I have never ever linked anything AI-generated. Yet I check the links and definitely don’t share AI slop intentionally.
If such a thing happened, it would have been like Musk’s “you don’t say” meme I received—passed by my colleagues with good intent.
The degree to which such a trust network spans depends on how reliably a node has worked so far. A strong connection would reinforce its subnetwork, while a failing (no longer trustworthy) node would weaken its connections.
Strong nodes would allow further connections, while weak ones would atrophy. It is essentially a case of a fitness landscape.
New Solutions Will Rely on Trust Networks
The changes we’ve made to our landscape with AI are irreversible. In one discussion I’ve had, someone suggested a no-AI subinternet.
It’s not feasible. Even if there were a way to reliably validate an internet user as a human (there isn’t), nothing would stop evil actors from copypasting AI slop semi-manually anyway.
In other words, we will have to navigate this information dumpster for the time being. To do that, we will rely on our trust networks.
Whatever new recruitment solution eventually emerges, it will employ extended trust networks. That’s what small business owners in a physical world already do. They reach out to their staff and acquaintances and ask whether they know anyone suitable for an open position.
Content creation and consumption are already evolving toward increasingly closed connections (paywalled content, Substacks, etc.), where we consciously choose what we read and from whom. Oh, and of course, the publishing platforms actively push recommendation engines.
Business connections? Same story. We will evolve to care even more about warm intros and in-person meetings.
Eventually, large parts of the internet will be an irradiated area where bots create for bots, while we will be building shelters of trustworthiness, where genuine human connection will be the currency.
Like hunters-gatherers. Like we did for millennia.
It’s not hard to guess that the response from smartass merchants would come almost immediately.
As much fun as we can make of those attempts to make a quick buck, the whole situation is way more interesting if we look beyond the technical and security aspects.
Shallow Perception of Autonomous AI Agents
What drew popular interest to the Stripe & OpenAI announcement was an intended outcome and its edge cases. “The AI agent will now be able to make purchases on our behalf.”
What if it makes a bad purchase?
How would it react to black hat players trying to trick it?
What guardrails will we have when we deploy it?
All these questions are intriguing, but I think we can generalize them to a game of cat and mouse. Rogue players will prey on models’ deficiencies (either design flaws or naive implementations) while AI companies will patch the issues. Inevitably, the good folks will be playing the catch-up game here.
I’m not overly optimistic about the accumulated outcome of those games. So far, we haven’t yet seen a model whose guardrails haven’t been overcome in days (or hours).
However, unless one is a black hat hacker or plans to release their credit-card-wielding AI bots out in the wild soon, these concerns are only mildly interesting. That is, unless we look at it from an organizational culture point of view.
“Autonomous” Is the Clue in Autonomous AI Agents
When we see the phrase “Autonomous AI Agent,” we tend to focus on the AI part or the agent part. But the actual culprit is autonomy.
And yet we can’t consider autonomy as a standalone concept. I often refer to a model of codependencies that we need to introduce to increase autonomy levels in an organization.
The least we need to have in place before we introduce autonomy are:
Explicit boundaries. We need to understand the limits within which we can act autonomously. Otherwise, we’d be both overwhelmed with possibilities and petrified by potential consequences.
Remove either, and autonomy won’t deliver the outcomes you expect. Interestingly, when we consider autonomy from the vantage point of AI agents rather than organizational culture, the view is not that different.
Limitations of AI Agents
We can look at how autonomous agents would fare against our list of autonomy prerequisites.
Transparency
Transparency is a concept external to an agent, be it a team member or an AI bot. The question is about how much transparency the system around the agent can provide. In the case of AI, one part is available data, and the other part is context engineering. The latter is crucial for an AI agent to understand how to prioritize its actions.
With some prompt-engineering-fu, taking care of this part shouldn’t be much of a problem.
Technical Excellence
We overwhelmingly focus on AI’s technical excellence. The discourse is about AI capabilities, and we invest effort into improving the reliability of technical solutions. While we shouldn’t expect hallucinations and weird errors to go away entirely, we don’t strive for perfection. In the vast majority of applications, good enough is, well, enough.
Alignment
Alignment is where things become tricky. With AI, it falls to context engineering. In theory, we give an AI agent enough context of what we want and what we value, and it acts accordingly. If only.
The problem with alignment is that it relies on abstract concepts and a lot of implicit and/or tacit knowledge. When we say we want company revenues to grow twice, we implicitly understand that we don’t plan to break the law to get there.
That is, unless you’re Volkswagen. Or Wells Fargo. Or… Anyway, you get the point. We play within a broad body of knowledge of social norms, laws, and rules. No boss routinely adds “And, oh by the way, don’t break a law while you’re on it!” when they assign a task to their subordinates.
AI agents would need all those details spoon-fed to them as the context. That’s an impossible task by itself. We simply don’t consciously realize all the norms we follow. Thus, we can’t code them.
Alignment, in turn, is all about having a world model and a lens through which we filter it. It’s all about determining whether new situations, opportunities, and options fit the abstract desired outcome.
Thus, that’s where AI models, as they currently stand, will consistently fall short.
Explicit Boundaries
Explicit boundaries are all about AI guardrails. It will be a never-ending game of cat and mouse between people deploying their autonomous AI agents and villains trying to break bots’ safety measures and trick them into doing something stupid.
It will be both about overcoming guardrails and exploiting imprecisions in the context given to the agents. There won’t be a shortage of scam stories, but that part is at least manageable for AI vendors.
Care
If there’s an autonomy prerequisite that AI agents are truly ill-suited to, it’s care.
AI doesn’t have a concept of what care, agency, accountability, or responsibility are. Literally, it couldn’t care less whether an outcome of its actions is advantageous or not, helpful or harmful, expected or random.
If I act carelessly at work, I won’t have that job much longer. AI? Nah. Whatever. Even the famous story about the Anthropic model blackmailing an engineer to avoid being turned off is not an actual signal of the model caring for itself. These are just echoes of what people would do if they were to be “turned off”.
AI Autonomy Deficit
We can make an AI agent act autonomously. By the same token, we can tell people in an organization to do whatever the hell they want. However, if we do that in isolation, we shouldn’t expect any sensible outcome. In neither of the cases.
If we consider how far we can extend autonomy to an AI agent from a sociotechnical perspective, we don’t look at an overly rosy picture.
There are fundamental limitations in how far we can ensure an AI agent’s alignment. And we can’t make them care. As a result, we can’t expect them to act reasonably on our behalf in a broad context.
It absolutely doesn’t limit specific and narrow applications where autonomy will be limited by design. Ideally, those limitations will not be internal AI-agent guardrails but externally controlled constraints.
Think of handing an AI agent your credit card to buy office supplies, but setting a very modest limit on the card, so that the model doesn’t go rogue and buy a new printer instead of a toner cartridge.
It almost feels like handing our kids pocket money. It’s small enough that if they spend it in, well, not necessarily the wisest way, it’s still OK.
Pocket-money-level commercial AI agents don’t really sound like the revolution we’ve been promised.
Trust as Proxy Measure of Autonomy
We can consider the combination of transparency, technical excellence, alignment, explicit boundaries, and care as prerequisites for autonomy.
They are, however, equally indispensable elements of trust. We could then consider trust as our measuring stick. The more we trust any given solution, the more autonomously we’ll allow it to act.
I don’t expect people to trust commercial AI agents to great extent any time soon. It’s not because an AI agent buying groceries is an intrinsically bad idea, especially for those of us who don’t fancy that part of our lives.
It’s because we don’t necessarily trust such solutions. Issues with alignment and care explain both why this is the case and why those problems won’t go away anytime soon.
Meanwhile, do expect some hilarious stories about AI agents being tricked into doing patently stupid things, and some people losing significant money over that.