
I ranted on 100% utilization a few years ago already. Let me add another thread to that discussion. We have a ton of everyday stories that show how brain-dead the idea of maximizing utilization is. Sometimes we can figure out how it translates to work organization as well. Interestingly, what Don Reinertsen teaches us is that queuing theory says exactly the same.
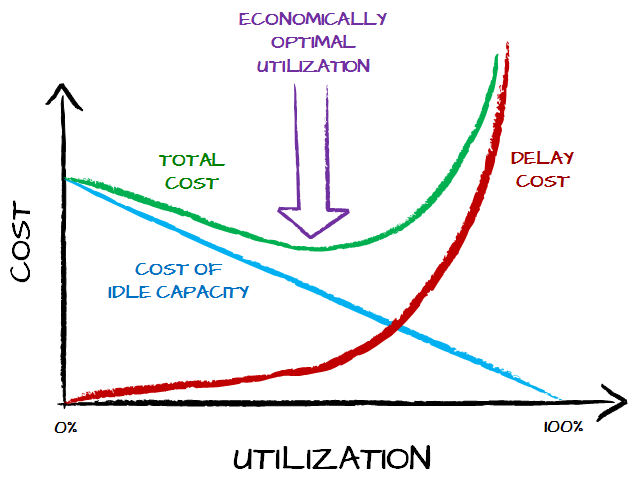
As we go up with utilization lead time or wait time goes up as well. Except the latter grows exponentially. It looks roughly like that.
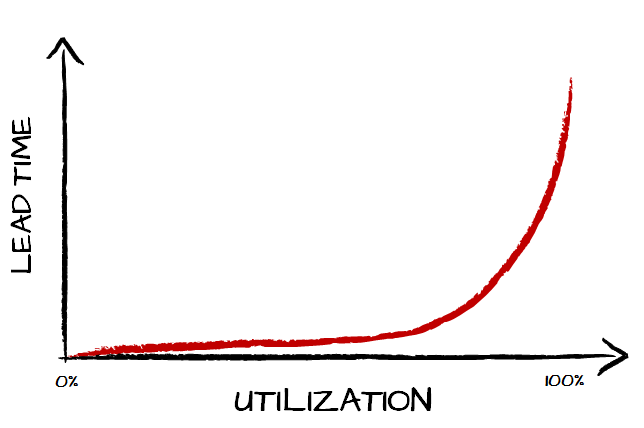
But wait, does it mean that we should strive to have as low utilization as possible? I mean, after all that’s where lead times are the shortest. This doesn’t sound sensible, right?
And it doesn’t make sense indeed. Cost of waiting is only one part of this equation. The other part is cost of idle capacity. We have people doing nothing thus they don’t produce value yet they cost something. From that perspective we have two cost components: delay cost related to long lead time and cost of idle capacity related to low utilization.
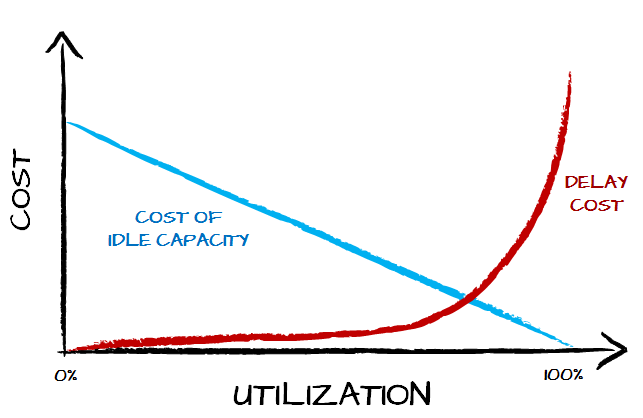
Of course the steepness of the curves would differ depending on the context. The thing is that the most interesting part of the chart is the sum of the costs which, naturally, is optimal at neither end of scale.
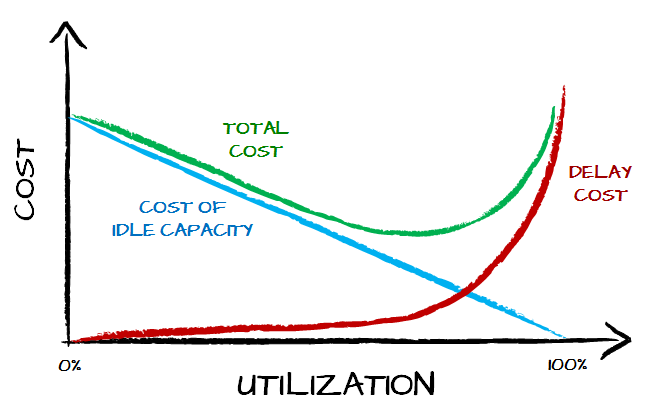
There is some sort of economic optimum for how much a system should be utilized to work most cost efficiently. There’s very good news for us though. The cost curve is the U-curve with flat bottom. That means that we don’t need to find the ideal utilization as a few percent here or there doesn’t make a huge difference.
We’d naturally think that the optimum is rather toward the more utilized part of the scale. That’s where the interesting part of the discussion starts.
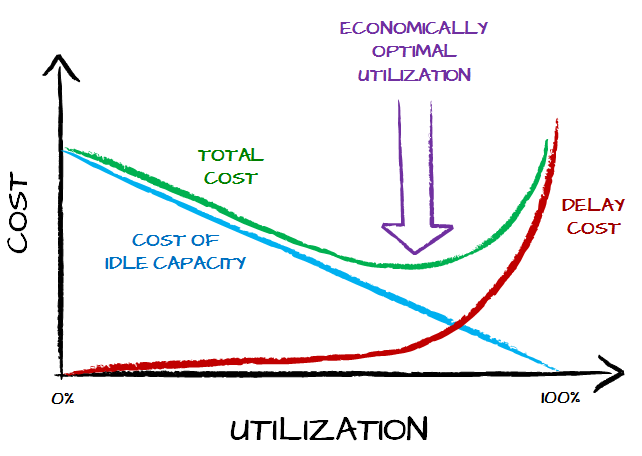
We have pretty damn good idea how much idle time or slack time costs us. This part is easy. Now, the tricky question: how much is shorter lead time worth?
Imagine yourself as a Product Owner in a funded startup providing an online service. Your competitor adds a new feature that generates quite a lot of buzz on social media. How long are you willing to wait to provide the same feature in your app? Would keeping an idle team all the time just in case you need to build something super-quickly be justified?
Now imagine that your house is on fire. How long are you willing to wait for a fire brigade? Would keeping an idle fire brigade just in case be justified?
Clearly, there are scenarios where slight differences in lead time are of huge consequences. We don’t want our emergency calls to be queued for a couple of weeks because a fire brigade or an ambulance service is heavily utilized. In other words steepness of one of the curves varies a lot.
Let’s look how different scenarios change the picture.
This sets the economically optimal utilization at very different levels. There are contexts where a lot of slack is perfectly justified. The ultimate example I can come up with are most of armies. We don’t expect them to be fully engaged in wars all the time. In fact the more slack armies have the better. Somehow we don’t come up with an idea that if an army has no war to run we better find them one.
Of course it does matter how they use their slack time, but that’s another story.
We don’t have that drastic examples of value of slack in software industry. However, we also deal with very different steepness of delay cost curve. Even if we don’t expect instant delivery we need to move quicker and quicker as everyone else does the same.
The bottom line is that our intuition about what is the cost of wait time (delay cost) is often flawed. This means that even if we are able to go beyond the myth of 100% utilization we still tend to overload our teams too much.
Oh, and if you wondered, at Lunar Logic our goal is to keep team’s utilization between 80% and 90%.






