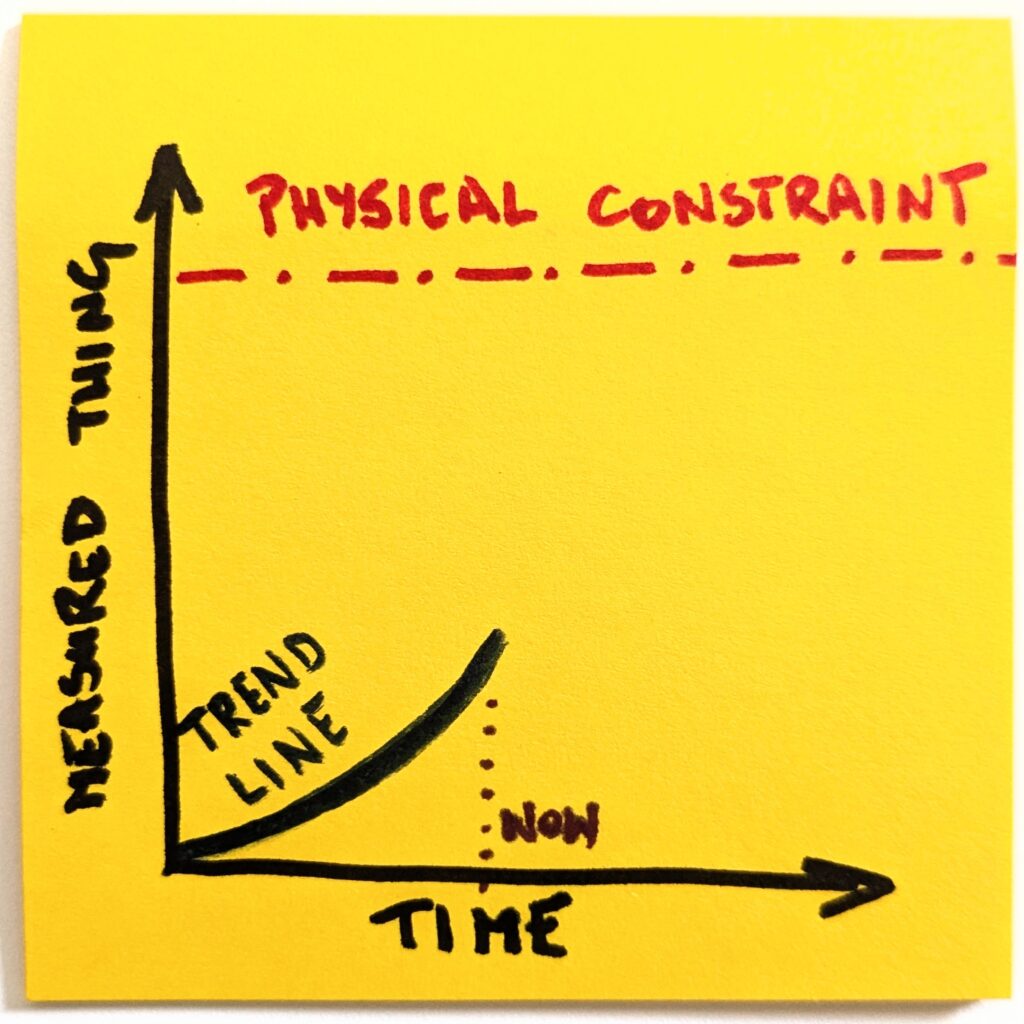
I made a few claims in the past stating that the average size of pull requests went up by an order of magnitude. I largely based it on hallway conversations with developers at Lunar Logic.
It turns out, the actual data is not that hard to check. Aaaand I was wrong.
AI Effect in PR Size
We pulled data from two very similar projects in terms of complexity, effort, and team size. Both codebases started greenfield and covered a few hundred pull requests in the analyzed period. There was even an overlap across the engineering team. The key difference? How we used AI.
The first project, let’s call it Helpful, happened in the pre-Claude era. While we already used AI to support development, it was predominantly autocomplete with occasional trips to ChatGPT to suggest solutions to pesky problems. All code was managed by developers in real time.
The second gig, I’ll call it Grateful, was full-on Claude. The basic assumption was that none of the code was written by hand. Engineering responsibilities were in context management, prompting, and review.
The bottom line? In an AI-heavy project, average PR size increased by a factor of 3.5.
Yes, I was wrong, but only about the relative scale of the change.
Tiny PRs Have Disappeared
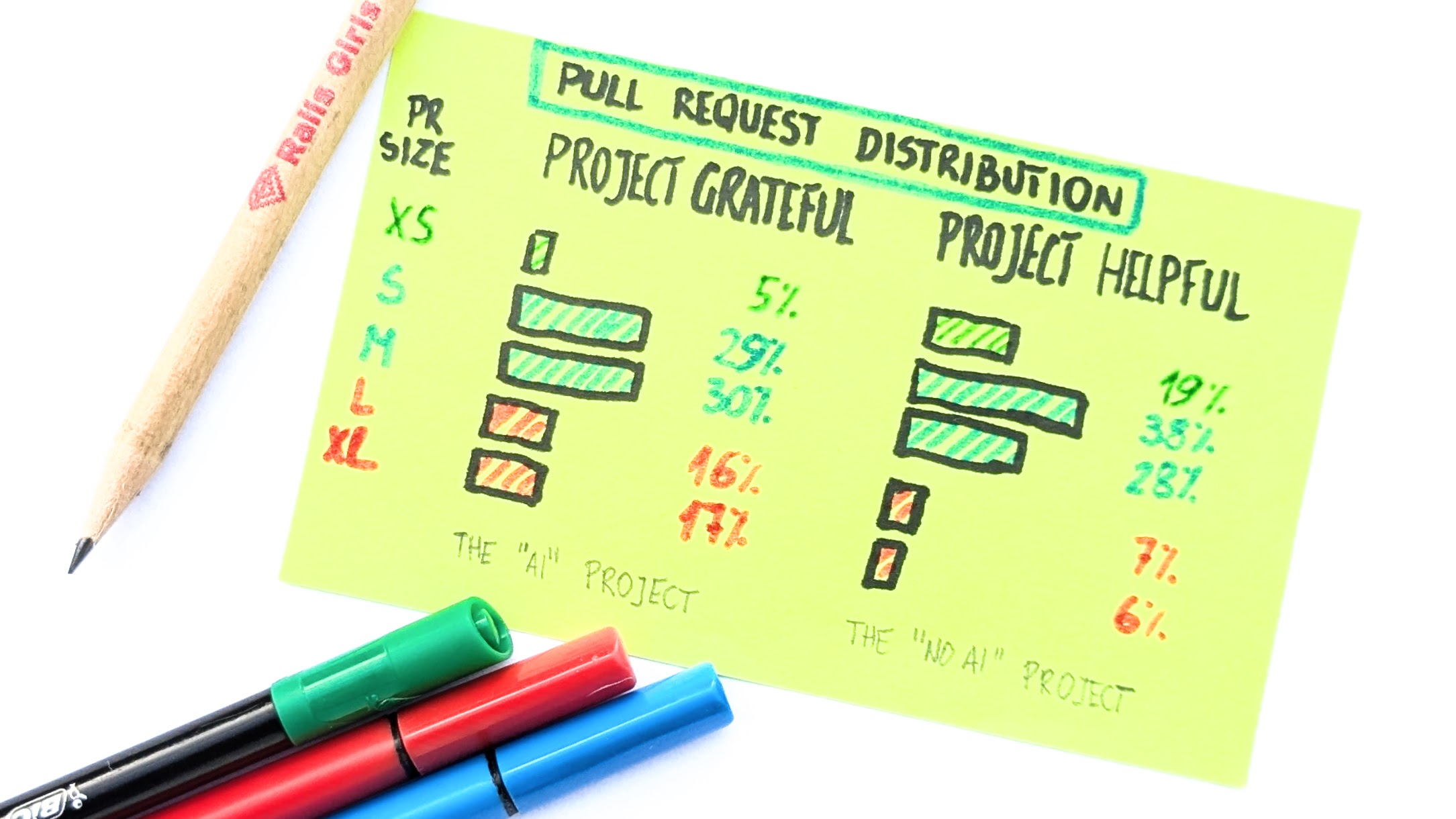
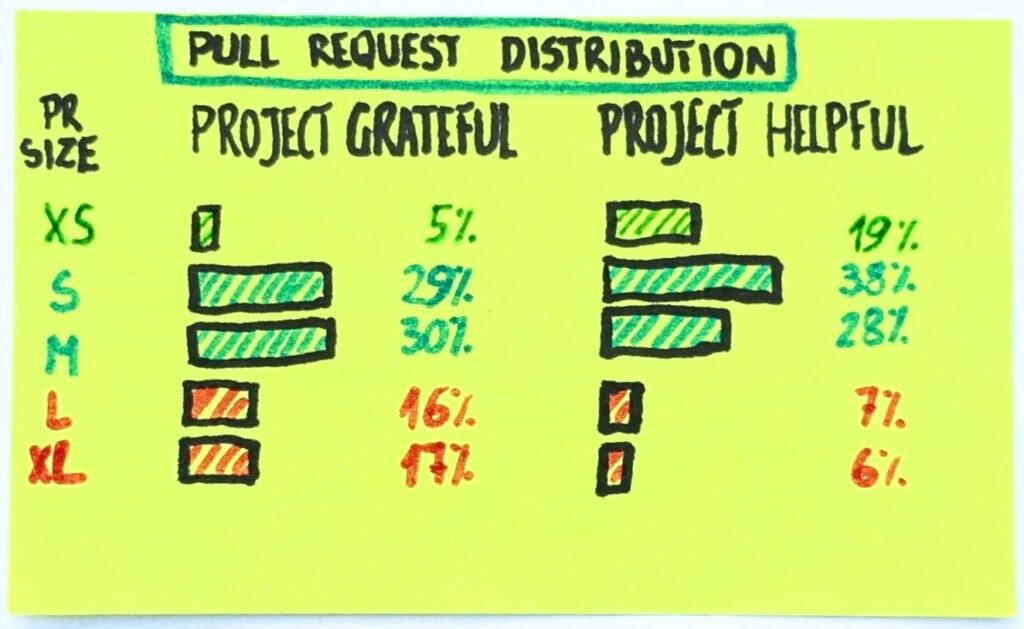
It would be easy to say that AI made us tackle bigger tasks. That’s not what data suggests, though. At least not when we look at the distribution of the PRs. Note: We sum the added and removed lines to calculate the PR size.
The bulk of PRs in both cases are small to medium ones. A few hundred lines of code tops (our cutoff line was 500). It was the bread and butter of engineering work. It still is.
Sure, in Project Helpful (the “no AI” one), these PRs were skewed toward smaller sizes, while in Project Grateful, the center of gravity was 100-200 lines of code heavier. Still, for an engineer familiar with the codebase, that’s not a challenge.
So, how come the average went up that much?
The answer is on the fringes. The smallest pull requests—the proverbial one-liners—all but disappeared. That’s the single most significant change. Tiny PRs were 1 in 5. Now they are 1 in 20.
The whole class of work items that was easiest to review is at risk of extinction. Let’s park this thought. I’ll be back to it soon.
Large PRs Are on the Rise
What we lost from the tiniest bits of work, we make up for with the largest.
There are almost 3 times as many large PRs.
The 90th percentile size increased 3x, from 600 lines of code to 1799 lines of code.
The outliers inflated even more—the largest PR in Project Grateful was 30k+ lines of code, almost 7 times bigger than its equivalent in Project Helpful.
Big just got bigger. And we get more of it, too.
Still, these chunks of code do not dominate the work. Definitely not just yet. However, there are enough of them to start paying attention.
Coincidentally, this is a class of items that is the most challenging for a reviewer. By now, you can probably guess where it is heading.
The Effects of Processing 3 Times as Many Lines of Code
No matter how I slice the data, it seems that we now deal with tasks that are roughly three times as big as they used to be.
The average PR size went up from 232 to 817 LoC—a 3.5x increase.
The median PR size went up from 66 to 210 LoC—a 3.2x increase.
The percentage of big and large PRs went up from 13% to 33%—a 2.5x increase.
Long story short, our brains process three times as much information per task as they used to. Common sense suggests that the review can’t be as thorough as it was when done in smaller bits.
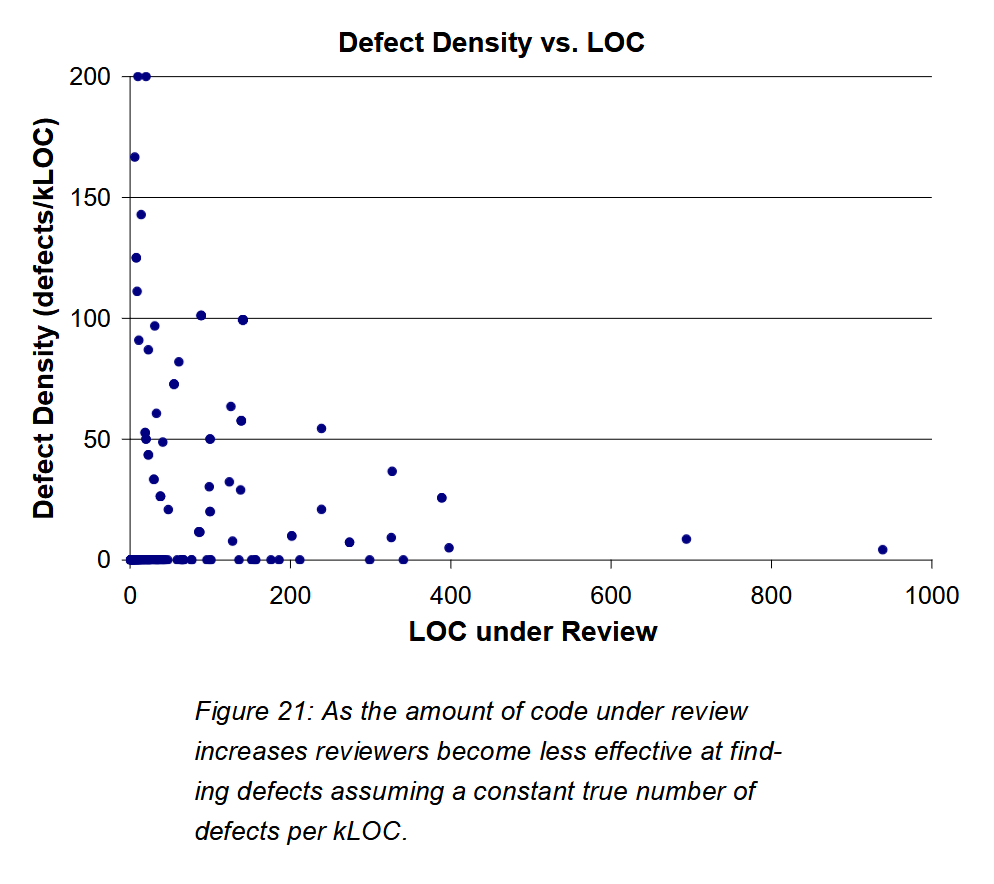
Research seems to concur. Well-recognized Smart Bear/Cisco study advises keeping pull request size below 200 lines. Above that size, reviewers start overlooking the issues.
“Reviewers are most effective at reviewing small amounts of code. Anything below 200 lines produces a relatively high rate of defects, often several times the average. After that the results trail off considerably; no review larger than 250 lines produced more than 37 defects per 1000 lines of code.”
Executive summary: Heavy use of AI makes individual chunks of work larger, and thus, overall quality drops.
Quality Drop Is Not Inevitable But Highly Likely
If we consider the changes, none of them seems inevitable. I mean, we can tell Claude Code to work in smaller chunks so it’s more convenient to review. Heck, we can make it use the annotation technique advised by the Smart Bear study. As a result, we should sustain most of the quality standards.
There’s only one issue. We won’t do any of these.
It would require engineers to artificially throttle their coding agents. It would mean more back-and-forth between humans and their tools. It would work against our “laziness” instincts.
If an agent handles a big task, why should we split it into smaller ones and review them gradually one by one, again? Isn’t it more effective to have the whole thing run at once rather than stopping it each time it approaches 200 lines of code changes? (By the way, it isn’t, but that’s another discussion.)
Finally, we get the perceived efficiency gains right here, right now, while the cost of lower quality is deferred to the future. Sadly, sticking to the engineering practices that kept the quality high seems highly unlikely.
As the capabilities of the models allow them to handle larger and larger coding tasks, the typical pull request size will go up.
As a result, reviewers will overlook more and more defects.
The fact that reviewers don’t dive deeply into the code conceptually will only exacerbate the quality issue.
Thus, we will increasingly develop software riddled with defects.
Said defects will add rework for coding agents and humans alike.
The pace of delivery of value-adding items will necessarily slow down, as more effort goes into rework (and rework of rework).
We will go so much faster, only to go as slow as we did in the past. Or slower still. That is, assuming that we stick to the idea of the human reviewer in the loop. And that’s not granted.
For decades, we tried to learn to work in small batches. The hard way, let me add. Now, with AI, we’re making a U-turn as if none of it mattered. I have bad news. It still does. It was never a software-specific thing. In fact, we stole it from manufacturing in the first place.
We will relearn small batches. Sooner than we think.
The last couple of years have been riddled with speculations about how AI will change the world. Software development and the broader IT industry are among the most affected contexts. Things are changing. The future is uncertain.
In such a landscape, it’s easy to subscribe to any speculation, like the infamous doom and gloom Citrini prediction. Before we fall for that, though, let’s look at the historical data.
It’s Q2 2026. If the AI predictions had been correct, then:
Why would they? After all, no one learns to code these days, because “everybody is now a programmer.”Courtesy of Jensen Huang.
If you want concrete data, since last autumn, AI writes 90% of the code. Yup, that’s Dario Amodei.
No one drops a tear over developers, though, because we already see how AI is in the midst of wiping out half of entry-level white-collar jobs. That’s Dario Amodei, too.
Yeah, I get your skepticism. That’s not reality I see around either. Fear not, however. Software engineers will go extinct this year. This time for real, says Dario Amodei. This time, we can trust him. For sure. Probably. Maybe.
Each time such an alarmistic prediction emerges, I ask one question: If X is true, what does the endgame look like?
What Is the Endgame?
I borrowed the idea of endgame from gaming, duh! Some gaming genres are built around a character progression. However, when a player character reaches the maximum level, the original game engine ceases to work. There’s no more level to grind. No more progression to make.
Thus, the endgame content was born. These are parts of a game designed specifically for max-level characters to keep the players interested. Typically, these are increasingly challenging. This time, the goal is not progress, but mastery. It’s like a game in a game.
The endgame content responds to the question of a hypothetical newbie player: “What happens if I play this game and keep progressing with my character?”
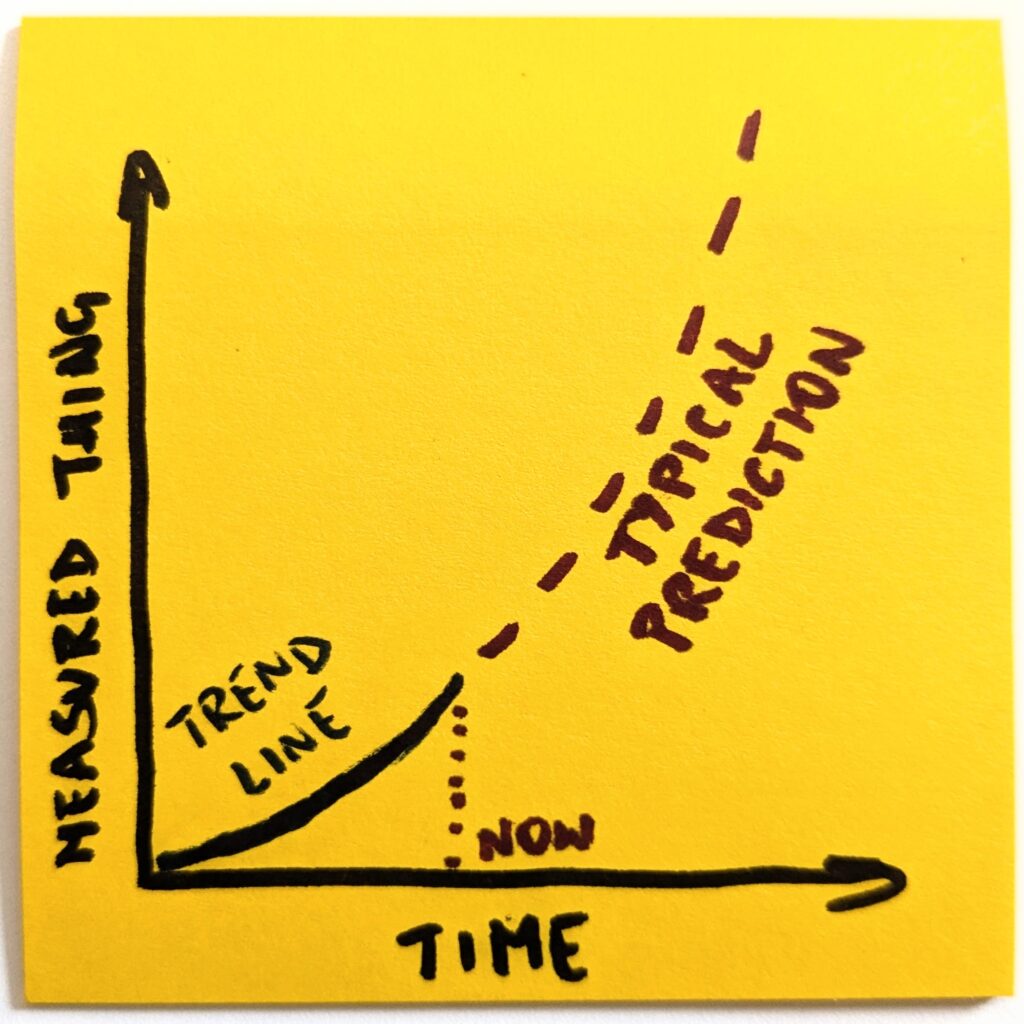
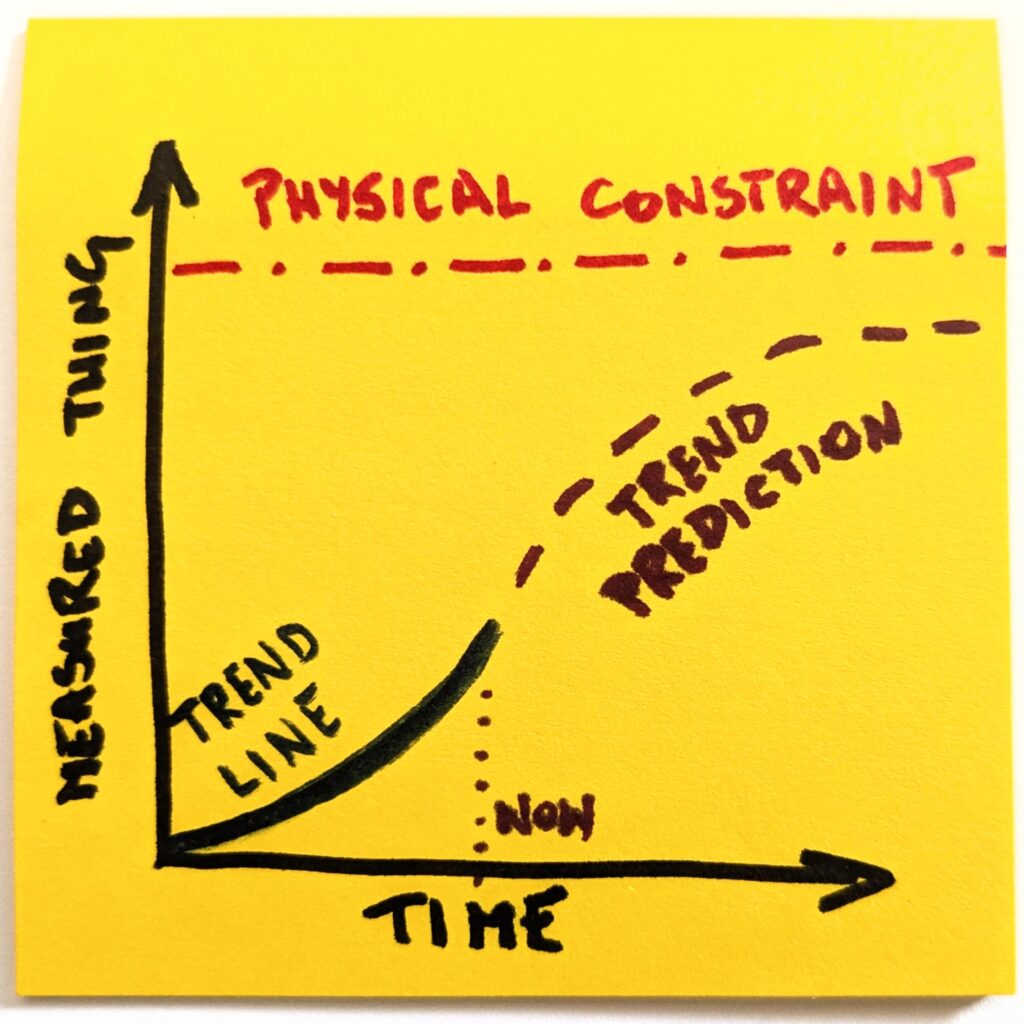
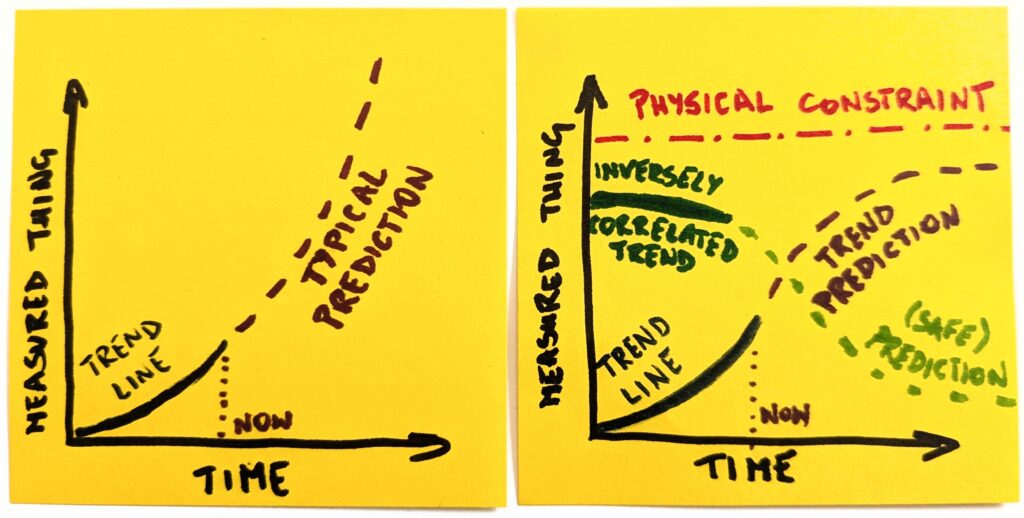
The question is interesting because we can envision the progression and intuitively realize that it can’t last indefinitely. At some point, an external constraint would impose itself, and our linear approximation of the trend (leveling up in this case) would break.
Thus, the question: What does the endgame look like?
The Endgame Question Is More Than Relevant in Business
If we look at market trends, the dynamics are surprisingly analogous. It’s not a game, so we don’t control the trends, but they’re there, sure enough. And they can’t last indefinitely. There’s always an external constraint that will impose itself.
The market share can’t go higher than 100%. The exponential growth can’t last more than a few years. Businesses need to make a profit eventually. And so on.
Now, if we ask the right questions, we don’t need to wait for the change to happen to see how the landscape will evolve. Better yet, we might see other facets of the change. Think of it as ripple effects. Then, suddenly, the landscape is richer, and we may come to very different conclusions from those we’d make if we looked at a trend in isolation.
A good example is what’s been dubbed a SaaSpocalypse—a recent devaluation of many SaaS businesses. What some perceived as the new trend predicting the end of SaaS, I consider merely a regression to the mean.
If this trend continued, the purchase price of these “old-school” product companies would be a bargain. They have healthy financials. Some have just recorded the best year ever. Unlike some of the tech scene darlings, they’re making actual profits. Plenty of them. Fundamentally, little has changed for these companies short- and mid-term.
It’s then relatively easy to see the endgame. The trend won’t continue too far, as eventually it would mean buying a dollar for fifty cents.
The Interconnected Trends and Second-Order Consequences
The endgame question is even more interesting whenever there’s no obvious limiting condition (like “you can’t have more than 100% of market share”). A good example is how AI affects coding.
We see increasing AI use in code generation. It’s not anywhere close to 90%, sure, but no one challenges that we’re doing more of that. Also, it’s obvious that AI agents can generate tons of code. And then some. No sweat.
The trend, then, suggests that we will have more and more of AI-generated code. Let’s then draw the trend line to the future and ask: What does the endgame look like?
Given how increasingly useful AI tools are, there’s no stopping the trend. At this pace, we will soon generate more code than we can reasonably review as we go. Once we stop the just-in-time code review, we will lose comprehension of what’s at the code level in our products.
These are second- or third-order consequences of code-generation capabilities we have thanks to AI tools. And these are precisely the considerations that any product business should take into account these days.
These are far more interesting than boasting about how much code is AI-generated. As a customer, I couldn’t care less whether you generate 30% of your code. Or 90%. Or none at all. I do care whether the product solves my problem now and whether it will be technically sustainable in a year from now.
The reason why the endgame question is so powerful is that it skips the current condition and jumps directly to the future state:
What will be new or different once this new thing becomes the norm?
When does the trend become unsustainable?
How do correlated trends behave?
Think of it as a model. We look at one thing and have historical data on how it has behaved so far. Now, the simplest possible thing is to extend the trend line indefinitely into the future.
Except, as we already established, things do not work like this. In no reality does OpenAI have 8 billion paying ChatGPT users. So, before we predict the future, we consider external constraints.
Once we make it explicit, it becomes obvious that a naive version of the future will not happen. Even if we assume the most optimistic scenarios, the trend line will have to change its shape.
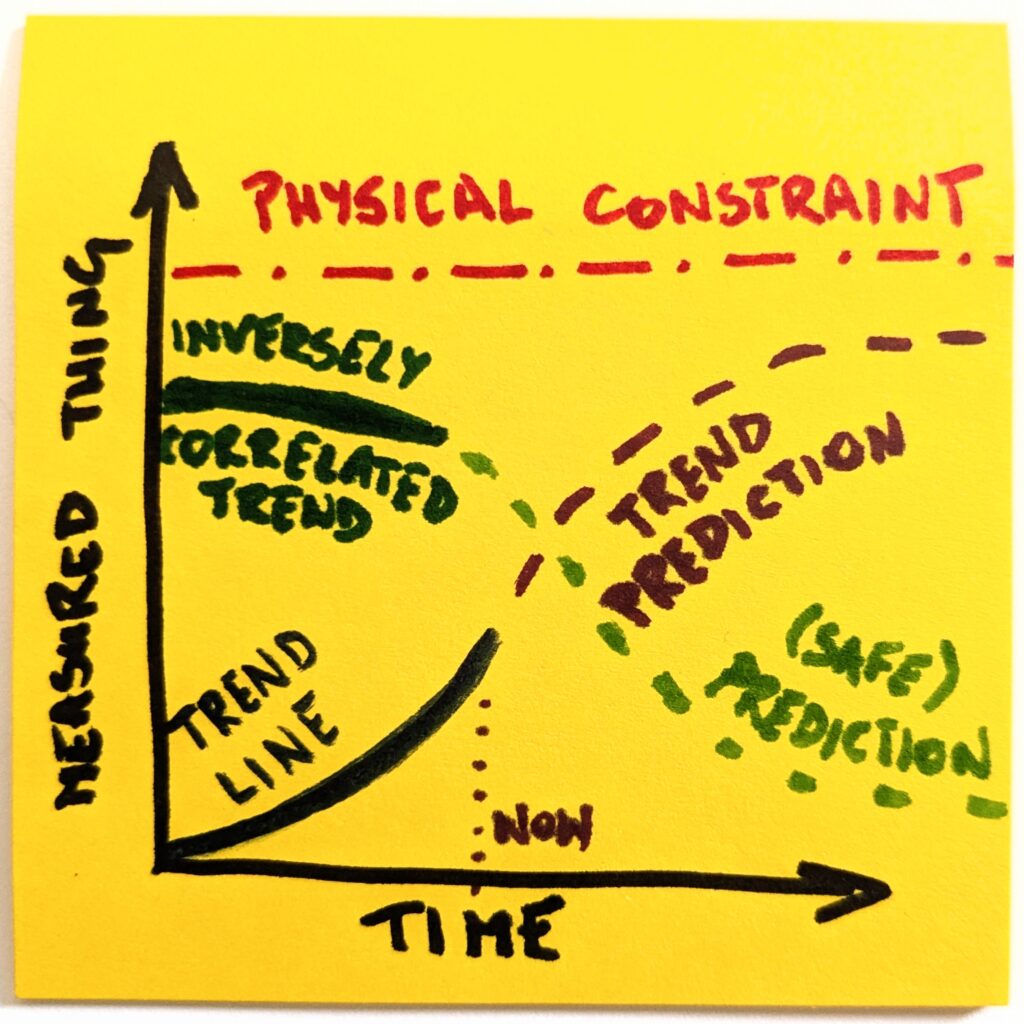
Well, that’s different now, thank you. But we’re not done yet. The most interesting things happen at the intersection. We can ask ourselves which other trends are correlated with whatever we focus on.
Like, if there’s more of this, there should also be more of that. Or vice versa, if there’s more of this, there should be less of that. As with our example, if we generate more and more code, there will necessarily be less technical comprehension. The stronger one is, the weaker the other will become.
Since we already have a clearer picture of the landscape, it’s not that hard to predict how an inversely correlated thing will change. And to what degree. Suddenly, we are equipped to ask questions about second-order consequences.
That’s where the endgame question shines. Instead of boasting about which big tech generates more code or predicting when developers go extinct, we may consider possible futures.
Human in the Loop and Coding
To run a quick example I touched on earlier, let’s consider AI and coding. Dario Amodei is wrong about how fast his AI models will take over coding. But it’s not because of the lack of capabilities of said models. I mean that too, but he knows more about these capabilities than you or me, and maybe he has all the right to believe it’s a technical problem that’s going to be fixed eventually.
He’s wrong because he considers code generation in a surprisingly isolated sandbox. If we were to believe Amodei’s predictions, we would have to assume that human-in-the-loop will be gone from software engineering.
I mean, physically, we can keep humans there, but they will have no real role. They’d be overloaded and incapable of good judgment. In fact, it’s already happening. Speculatively, though likely, in recent wars, humans-in-the-loop had the final call with decisions about strikes. Yet, you can’t expect good judgment if someone is expected to make 80 life-or-death decisions per hour.
There might still be a human body in the loop. The judgment, though? With enough cognitive load, it’s gone.
Just compare these two predictions. The first is a naive one, and considers a thing in isolation. The second attempts to understand what would change and how if the current trends stay with us. These two look very different.
The Endgame Question for Coding
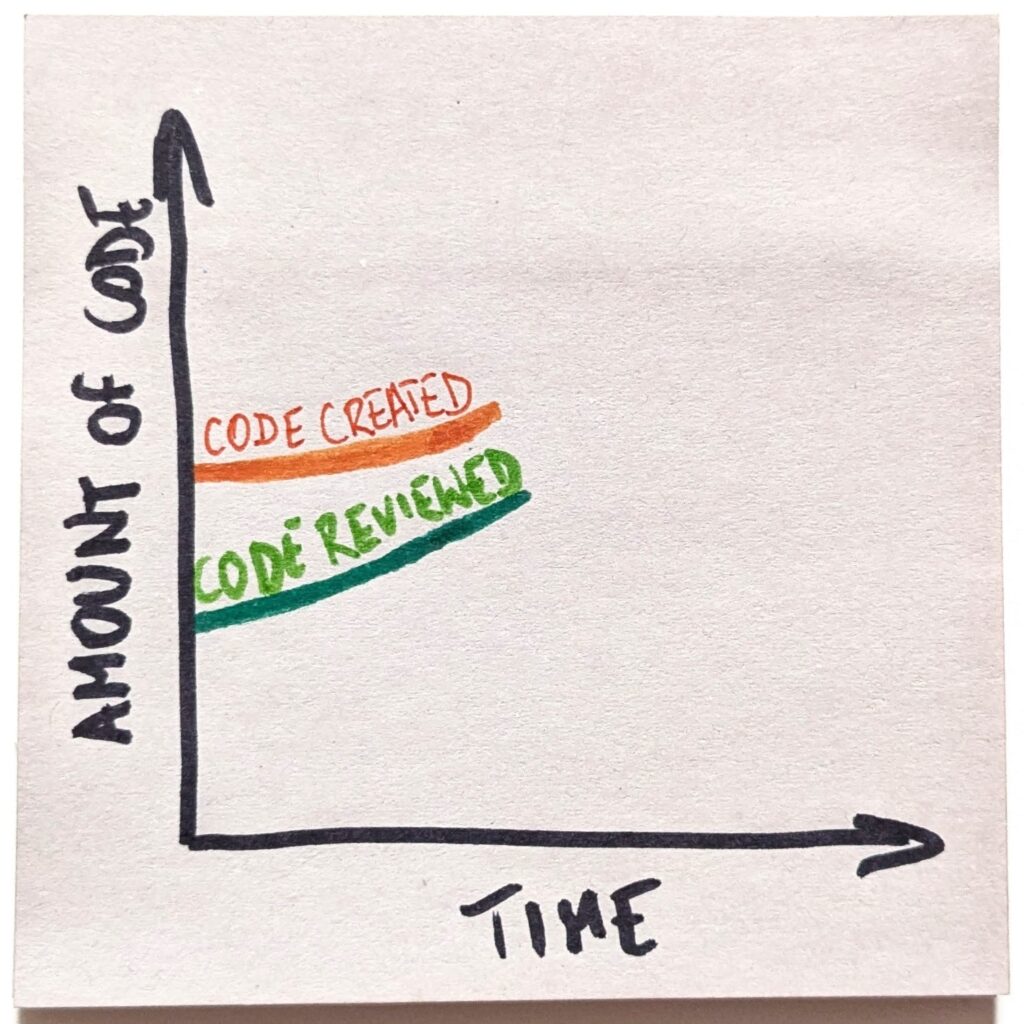
So let’s look at what answers the endgame question yields in the coding example. In the past decades, we’ve been creating a growing amount of code. And yet, code review as a practice has also been increasingly popular.
AI has introduced a foreign element to our system. Now we can easily generate as much code as we want. Increasingly, we do. That changes the current dynamics of software development trends.
But wait, so far, the “code review” trend has been all good. The practice has been growing in popularity, despite the fact that, as a whole, we were developing more code.
Hell, one way of looking at it is that all code has been reviewed, since the developer creating it was doing a sort of review as part of the creative process.
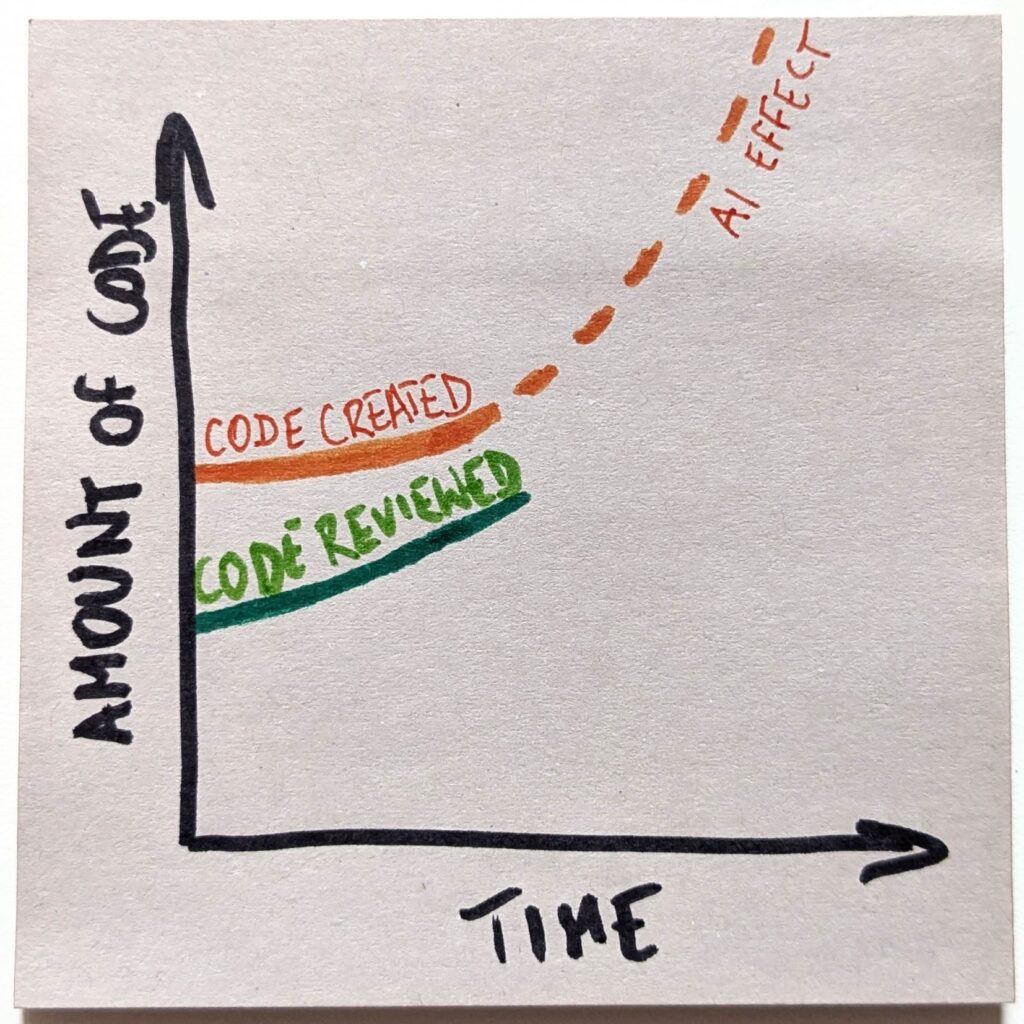
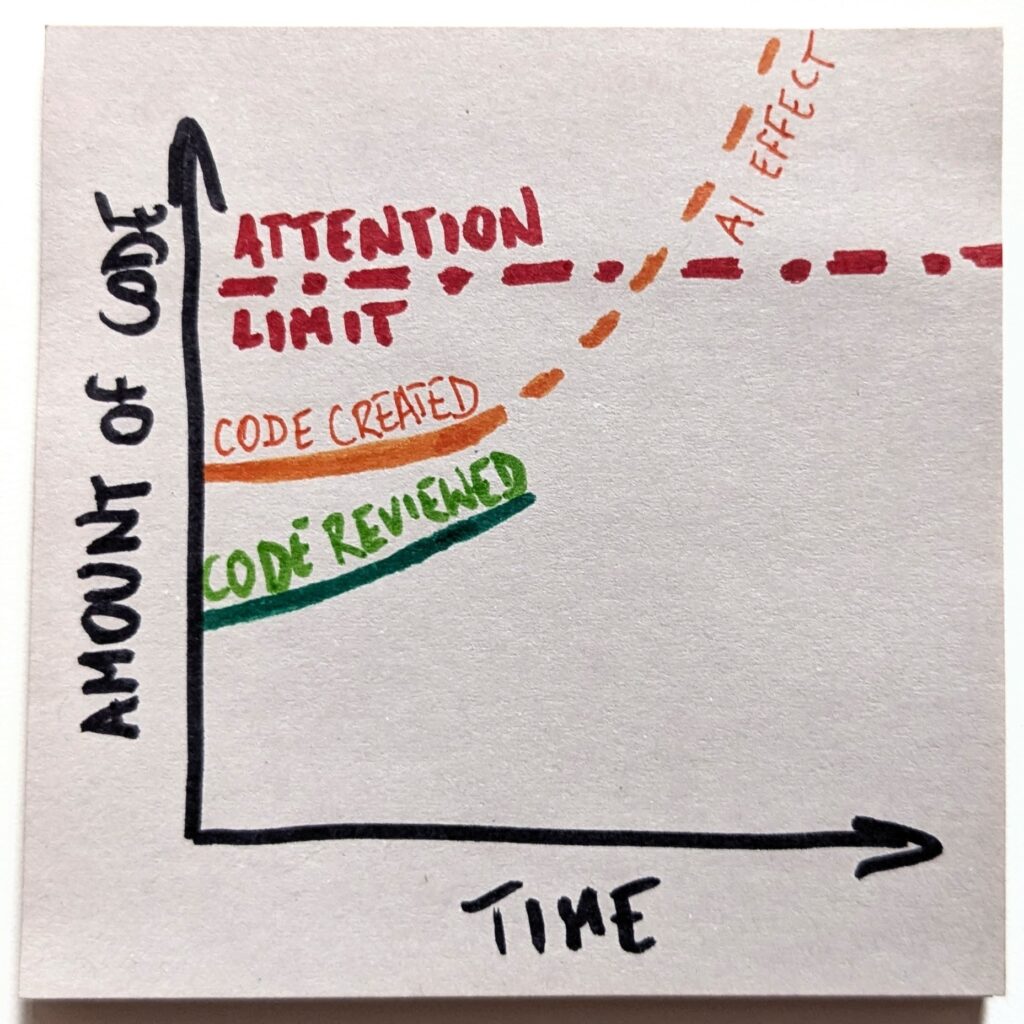
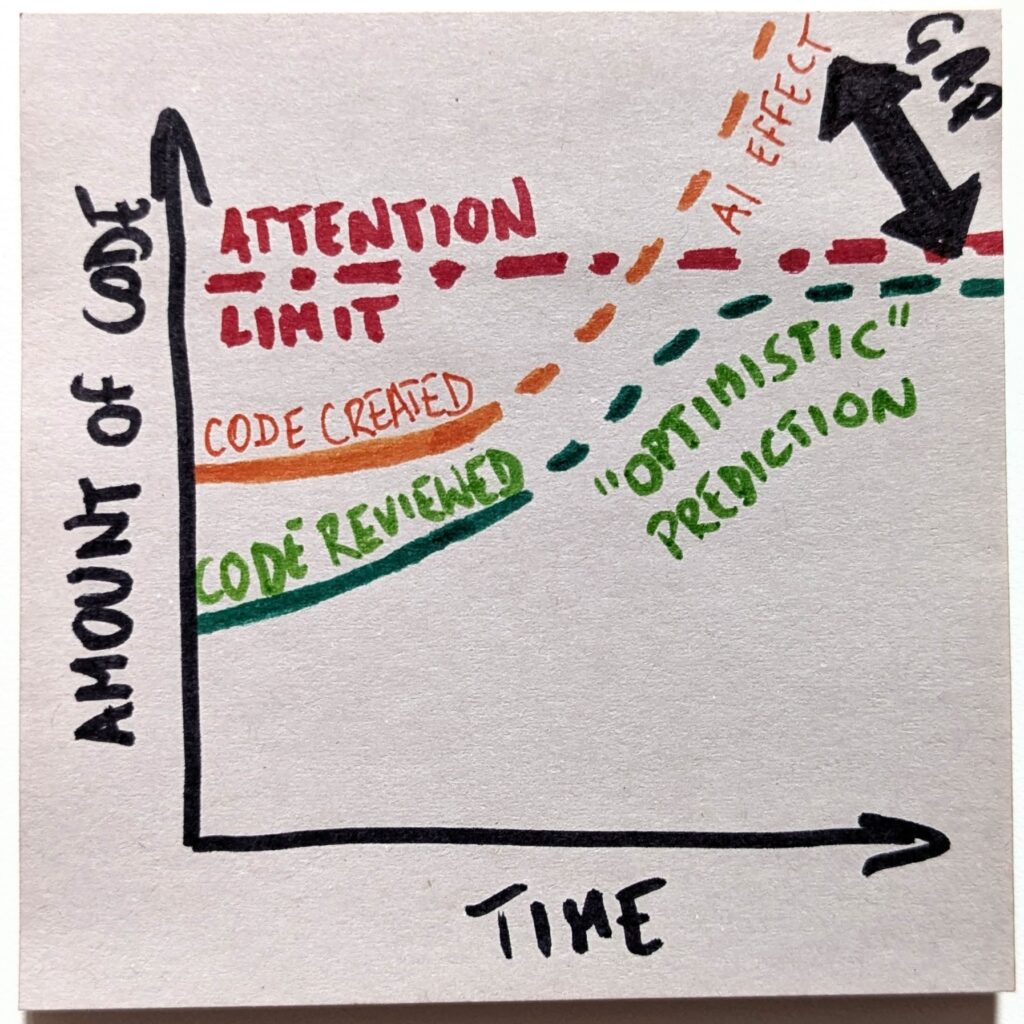
The only problem is that code review is a cognitive task that requires attention. And we have a limited pool of it. If we suddenly needed to review 10x as much code, we don’t have enough engineers to handle that.
Even if we try to keep up, which I call an “optimistic” scenario here, we eventually hit the ceiling. There’s no more available attention to pay.
A side note: we could argue that we actually raise the limit by freeing developers from writing code, so they have more time to review it. That’s fair. However, we also claim we don’t need no new developers (so we don’t train them) and lay them off (so they change industries). Effectively, we’re working the limit line in both directions. In either case, even if it goes somewhat up, we’ll cross it soon enough.
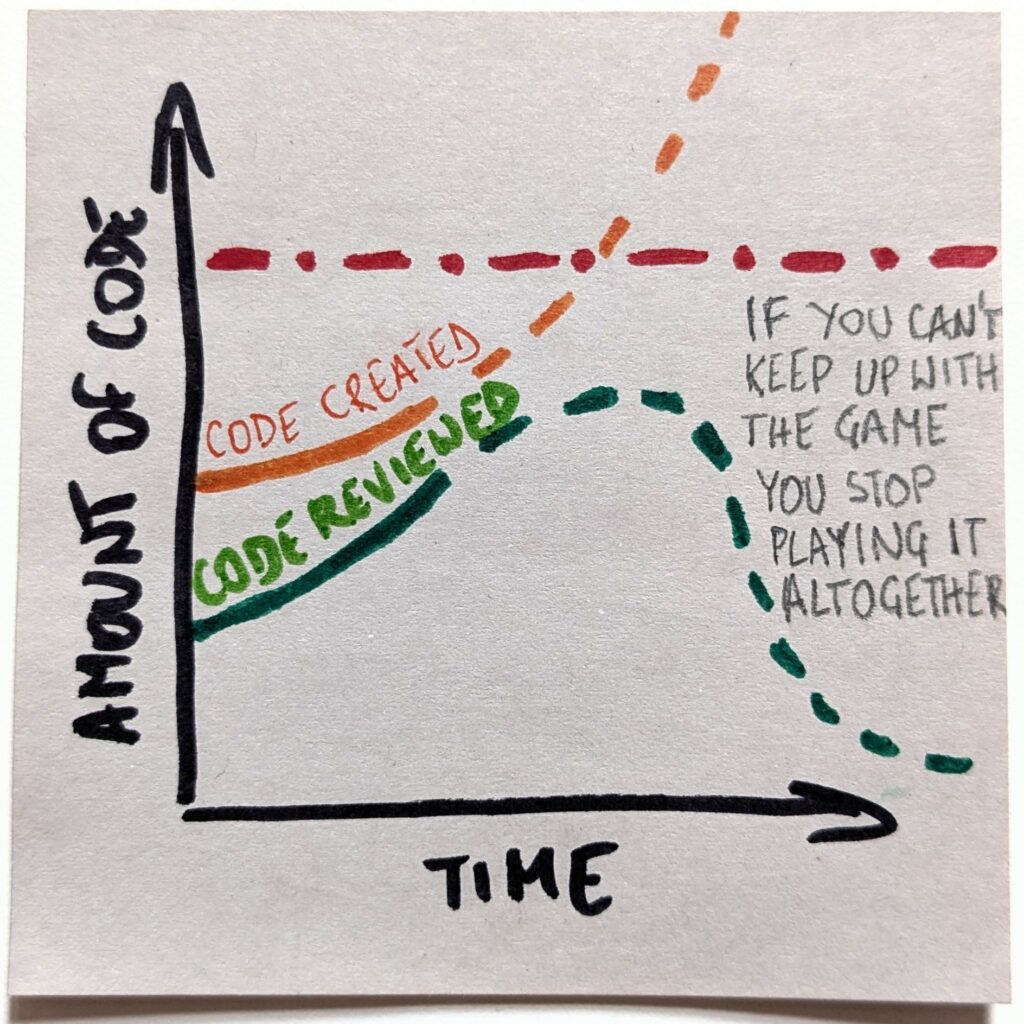
With that, we’ll create a gap between the amount of code we create and the loads we are capable of reviewing. And that gap will only keep growing. Fast.
That, in turn, is the exact reason the “optimistic” scenario will not happen. Playing a losing game is no fun. Even less so if that’s an increasingly losing game. The only sensible expectation is that we will stop playing the game altogether.
The new reality doesn’t mean stopping the reviews entirely. But we’ll need to pick our battles. And we’ll need to be increasingly picky about picking them. We’ll choose only the most critical parts of the code and maintain active knowledge of them.
Second-Order Consequences of the Coding Endgame
Things get even more interesting when we consider ripple effects. Before AI, basically, all the code was read. I mean, a human wrote it, so part of the process was looking at the thing. The “code read” curve was identical to the “code created” one.
However, as we stop writing code ourselves and expect the code review rate to nosedive, we’ll look at a completely different reality. “Code read” line will detach from “code created” and will follow “code reviewed.”
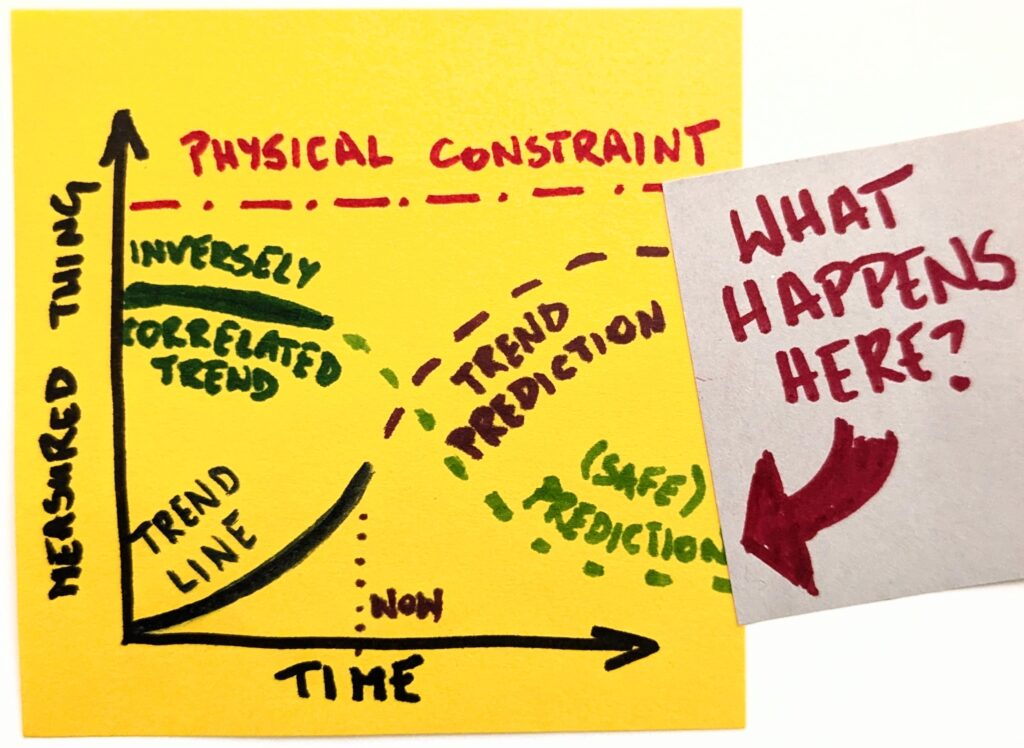
Now, that’s interesting. There is more code, but save for very few carefully chosen code bases, we neither read nor understand it. It’s as if there were islands of comprehension in a black-box ocean. That is, unless we fundamentally change something. So, are we ready to run critical systems on software we can’t comprehend? Because that’s what the endgame looks like.
And that’s but one example why the endgame question is such a neat trick. The moment we start asking it, we start seeing scenarios that go way beyond the hype. It’s not just “Claude Code is so awesome; it can do the coding for me.” It’s “Would I trust a vibe-coded e-commerce with my credit card number?” Or even “How would I feel if Visa or MasterCard ran on software no human comprehends?”
The Ultimate Question
Now, I know I rode the example of AI in coding in this post. The applicability of the endgame question is way broader, though. It literally pops up anytime someone makes a kind of bold prediction, well, about anything. You know, the type of “AI is capable of erasing half of white-collar jobs, so AI labs will get unfathomably rich,” or something along the same lines.
What does the endgame look like? Well, we make half of the knowledge workers unemployed, and who’s paying the AI bills, again?
Or take this: “AI will take over content generation as it can create 100x times as much as humans can, no sweat.” What does the endgame look like? We don’t have 100x as much attention, so the vast majority of the generated content will not be consumed at all. We may have the effect of bad money driving out good, but we won’t fundamentally have use of more content.
“Thanks to AI capabilities, we’ll see a surge of new products. Anyone will be able to run a product now.” What does the endgame look like? Again, the attention constraint (or the demography) suggests we won’t have 100x as many customers. So, if anything, we’ll just increase the failure rate. While running a startup is already unappealing, it will become even less of a winning proposition, which will actively drive people away from that path.
“AI will automate applying for jobs.” What does the endgame look like? Both sides get automated to handle an increasing load. Eventually, it’s one AI agent negotiating with another to figure out whether a human is a good fit for an organization. The system is bound to be misaligned and thus gamed. What follows is that we’ll either accept hiring candidates who are increasingly unfit for the role (but who played the game better) or reinvent the hiring system altogether.
So before we jump on another bit of “CEO said a thing” journalism, it’s worth asking: if that’s true, what does the endgame look like?
As hilarious as it would be, given the topic, this post has not been AI-generated. 웃 https://okhuman.com/wLBTwg
Object-Oriented Development is a classic that revolves around the architectural concepts of many modern (object-oriented) programming languages.
I could go on with this list, yet you get the point. We create formalized approaches to programming to help us focus on specific aspects of the process, be it code architecture, workflow, business context, etc.
A bold idea: How about Care-Driven Development?
Craft and Care in Development
I know, it sounds off. If you look at the list above, it’s pretty much technical. It’s about objects and classes, or tests. At worst, it’s about specific work items (features) and how they respond to business needs.
But care? This fluffy thing definitely doesn’t belong. Or does it?
An assumption: there’s no such thing as perfect code without a context.
We’d require a different level of security and reliability from software that sends a man to the moon than from just another business app built for just another corporation. We’d expect a different level of quality from a prototype that tries to gauge interest in a wild-ass idea than from an app that hundreds of thousands of customers rely on every day.
If we apply dirty hacks in a mission-critical system, it means that we don’t care. We don’t care if it might break; we just want that work item off our to-do list, as it is clearly not fun.
By the same token, when we needlessly overengineer a spike because we always deliver SOLID code, no matter what, it’s just as careless. After all, we don’t care enough about the context to keep the effort (and thus, costs) low.
If you try to build a mass-market, affordable car for emerging markets, you don’t aim for the engineering level of an E-class Mercedes. It would, after all, defeat the very purpose of affordability.
Why Are We Building That?
The role of care doesn’t end with the technical considerations, though. I argued before that an absolutely pivotal concern should be: Why are we building this in the first place?
“There is nothing so useless as doing efficiently that which should not be done at all.”
Peter Drucker
It actually doesn’t matter how much engineering prowess we invest into the process if we’re building a product or feature that customers neither need nor want. It is the ultimate waste.
In this context, care means that, as a developer, I want to build what actually matters. Or at least what I believe may matter, as ultimately there is no way of knowing upfront which feature will work and which won’t.
So what do I suggest as this fluffy idea of Care-Driven Development?
In the shortest: Giving a shit about the outcomes of our work.
The keyword here is “outcome.” It’s not only about whether the code is built and how it is built. It’s also about how it connects with the broader context, which goes all the way down to whether it provides any value to the ultimate customers.
Yes, it means caring about understanding product ownership enough to be able to tell a value-adding outcome from a non-value-adding one.
Yes, it means caring about design and UX to know how to build a thing in a more appealing/usable/accessible way.
Yet, it means caring about how the product delivers value and what drives traction, retention, and customer satisfaction.
Yes, it means caring about the bottom-line impact for an organization we’re a part of, both in terms of costs and revenues.
No, it doesn’t mean that I expect every developer to become a fantastic Frankenstein of all possible skillsets. Most of the time, we do have specialists in all those areas around us. And all it takes to learn about the outcomes is to ask away.
With a bit of luck, they do care as well, and they’d be more than happy to share.
Admittedly, in some organizations, especially larger ones, developers are very much disconnected from the actual value delivery. Yet, the fact that it’s harder to get some answers doesn’t mean they are any less valuable. In fact, that’s where care matters even more.
The Subtle Art of Giving a Shit
Here’s one thing to consider. As a developer, why are you doing what you’re doing?
Does it even matter whether a job, which, admittedly, is damn well-paid, provides something valuable to others? Or could you be developing swaths of code that would instantly be discarded, and it wouldn’t make a difference?
If the latter is true, and you’ve made it this far, then sorry for wasting your time. Also, it’s kinda sad, but hey, every industry has its fair share of folks who treat it as just a job.
However, if the outcome (not just output) of your work matters to you, then, well, you do care.
Now, what if you optimized your work for the best possible outcome, as measured by a wide array of parameters, from customer satisfaction to the bottom-line impact on your company?
It might mean less focus on coding a task at hand, but more on understanding the whys behind it. Or spending time on gauging feedback from users instead of knowing-it-all. Definitely, some technical trade-offs will end up different. To a degree, the work will look different.
Because you would care.
Care as a Core Value
I understand that doing Care-Driven Development in isolation may be a daunting task. Not unlike trying TDD in a big ball of mud of a code base, where no other developer cares (pun intended). And yet, we try such things all the time.
Alternatively, we find organizations more aligned with our desired work approach. I agree, there’s a lot of cynicism in many software companies, but there are more than enough of those that revolve around genuine value creation.
And yes, it’s easy for me to say “giving a shit pays off” since I lead a company where care is a shared value. In fact, if I were to point to a reason why we haven’t become irrelevant in a recent downturn, care would be on top of my list.
Lunar Logic shared values
But think of it this way. If you were an aerospace industry enthusiast, would you rather work for Southwest or Ryanair? Hell, ask yourself the same question even if you couldn’t care less about aerospace.
Ultimately, both are budget airlines. One is a usual suspect when you read a management book, and they need an example of excellent customer care. The other is only half-jokingly labeled as a cargo airline. Yes, with you being the cargo.
The core difference? Care.
Sure, there is more to their respective cultures, yet, when you think about it, so many critical aspects either directly stem from or are correlated with care.
Care-Driven Development
In the spirit of simple definitions, Care-Driven Development is a way of developing software driven by an ultimate care for the outcomes.
It encourages getting an understanding of the broad impact of developed code.
It drives technical decisions.
It necessarily asks for validating the outcome of development work.
It’s the art of giving a shit about how the output of our work affects others. No more, no less.
What followed was that software engineering had to be quite a holistic discipline. You wanted to store the data? Learning databases had to be your thing. You wanted to exploit the advantages of the internet boom? Web servers, hosting, and deployment were on your to-do list.
It was an essentially “whatever it takes” attitude. Whatever bit of technology a product needed to run, developers were picking it up.
Specialization in Software Engineering
The next few decades were all about increasing specialization. The increasingly dominant position of web applications fueled the rise of javascript, which, in turn, created front-end as a separate role.
Suddenly, we had front-end and back-end developers. And, of course, full-stack developers as a reference point to differentiate from. The latter has quickly become a topic of memes.
Oh, and mobile developers. Them too, of course.
The user-facing part has undergone further specialization. We carved more and more stuff for design and UX roles.
Back-end? It was no different. Databases have become a separate thing. Then, with big data, we’ve got all the data science. The infrastructural part has evolved into devops.
And then it went further. A front-end developer turned into a javascript developer, and that one into a React developer.
The winning game in the job market was to become deeply specialized in something relatively narrow, then pass a ridiculous set of technical tests and land an extravagantly paid position at a big tech.
The transition wouldn’t have happened without two critical factors.
Growth of Product Teams
First, the software projects grew in size. So did the product teams. As a result, there was more space for specialized (sometimes highly specialized) roles in just about any software development team.
Sure, there have always been highly specialized roles—engineers pushing an envelope in all sorts of domains. But the overwhelming majority of software engineering is not rocket science. It’s Just Another Web App™.
However, because Just Another Web App™ became increasingly larger, it was easier to specialize. And so we did.
Technology Evolution
The second factor that played a major role was the technology.
Back in the 90s, when you picked up C as a programming language, you had to understand how to manage memory. You literally allocated blocks of RAM. In the code. Like an animal. And then, with the next generation of technology, you didn’t need to.
The same thing happened with the databases. The first time I heard an aspiring developer claim that they neither needed nor wanted to learn anything about SQL because “RoR takes care of that for me,” I was taken aback.
But it made sense. The developer started their journey late enough, so they could have chosen a technology that hid the database layer from them entirely (and, unless supervised, made an absolute disaster out of the data structures, but that’s another discussion entirely).
And don’t even get me started about front-end developers whose knowledge of back-end architecture ends at knowing how to call an API endpoint. Or back-end developers who proudly resolve CSS as Can’t Stand Styling.
Ignore my grandpa’s complaints, though. The dynamic was there, and it only reinforced the trend for specialization.
The Bootcamp Kids
As if that all weren’t enough, the IT industry, still hungry for more specialists, turned into a mass-producing machine of wannabe developers.
With such a narrow specialization, we figured it might be enough to get someone through several weeks of a coding bootcamp, and voila! We got ourselves a new developer, high five, everyone!
Yes, a developer who can do rather generic tasks in only one technology, which covers just a small bit of the whole product stack, but a developer nonetheless.
The narrow got even narrower, even if the depth didn’t get deeper at all.
AI Disruption
Enter AI, and we are told we don’t need all these inexperienced developers anymore because, well, AI will do all that work, what don’t you understand?
The fact is that these narrow & shallow jobs are gone. The AI models generate boilerplate code just fine, thank you very much. Sure, the higher the complexity, the worse the output. But that’s not where those shallow skill sets are of any use.
Arguably, depth doesn’t help as much either.
We need breadth.
Since an AI model can generate a working app, it necessarily touches all its layers, from infrastructure, through data, back-end, front-end, to UX, design, and what have you.
Breadth over Depth
The big challenge, though, is that AI can hallucinate all sorts of “fun” stuff. If our goal is to ensure it does not, well, we need to understand a bit of everything. Enough of everything to be able to point (prompt) the AI model in the right directions.
A highly specialized knowledge can help to make sure we’re good with one part of a product. However, if it comes in the package of complete ignorance in other areas, it’s a recipe for disaster.
The new tooling calls for a good old “anything it takes” approach.
If that weren’t enough, the capability to generate code, especially when we talk about large amounts of rather basic code, potentially enables a return to smaller teams.
In the new reality, a developer becomes more of a navigator than a coder, and this role calls for a broader skill set.
Filling the Gaps
Increased technical flexibility is both a new requirement and an opportunity. At Lunar Logic, we work extensively with early-stage founders. That type of endeavor sways toward experimentation and, on many accounts, forgives more than working on established, scaled products.
On the other hand, the cost-effectiveness is crucial. The pre-pre-seed startups aren’t known to be drowning in money.
Examining how our work evolves thanks to AI tooling, I see similar patterns. For some products, the role of design and (arguably) UX is significantly lesser than for others. Consider a back-office tool designed to support an internal team in managing a complex information flow, as a good example.
A now viable option is to generate the whole UI with a tool such as v0, focusing on usability, which is but one aspect of design/UX, and we’re good.
Is the UI as good as designed by an experienced designer? Hell, no! Is it good enough within the context, though? You betcha! The best part? A developer could have done that. Given they know a thing or two about usability, that is. That knowledge? That’s breadth again.
I could go with similar examples in other areas, like getting CSS that’s surprisingly decent (and way better than something done by a Can’t Stand Styling developer), or a database schema that’s a leapfrog ahead of what some programming languages would generate for you out of the box (I’m looking at you, Ruby on Rails).
The thing is, every developer can now easily be more independent.
Full-Stack Strikes Back
The tides have turned. We have reversed the flow in both product team dynamics and technical skills required to be effective. That, however, comes at a cost of a new demand. We need more flexibility.
It’s not without a reason why experienced developers are still in high demand. They have been around the block. They can utilize the new AI tooling as an intellectual exoskeleton to address their shortcomings (precisely because they understand their own shortcomings). Thanks to extensive experience, such developers can guide AI models to do the heavy lifting (and fix stuff when AI breaks things in the process).
That’s the archetype of a software engineer that we need for the future. Understandably, many developers are caught off guard as they were investing in a completely different path, sometimes for all the wrong reasons (like, it’s a meh job, but at least it pays great).
These days, if you don’t have a passion to learn to be a full-stack developer, it will be harder and harder to keep up.
A disclaimer: there have always been and will always be edge-case jobs that require high specialization and deep knowledge. Nothing changes on this account. It’s just that the mainstream (and thus, a bulk of “typical” jobs) is going to change.
Reinventing the Learning Curve
That, of course, creates a whole new challenge. How do we sustain the talent pool in the long run? After all, we keep hearing that “we don’t need inexperienced developers anymore.” And the argument above might be read as support for such a notion.
It’s not my intention to paint such a picture.
I’ve always been a fan of hiring interns and helping them grow, and it hasn’t changed.
You can bet that many companies will not view it in this way.
Decades back, we were capable of learning the ropes when we needed to allocate a block of memory manually each time we wanted to use it. I don’t see a reason why shouldn’t we learn good engineering now, with all the modern tools.
Sure, the way we teach software development needs to change. I don’t expect it to dumb down. It will smart up.
Then, we’ll see a renaissance of full-stack developers.
There’s one observation that I pretty much always bring to the table when I discuss the rates for our work at Lunar Logic. The following is true whenever we are buying anything, but when it comes to buying services the effect is magnified. A discussion about the price in isolation is a wrong discussion to have.
What we should be discussing instead is value for money. How much value I get for what I pay. In a product development context, the discussion is interesting because value is not provided simply by adding more features. If it was true, if the following dynamics worked—the more features the better the product—we could distill the discussion down to efficient development.
For anyone with just a little bit of experience in product development such an approach would sound utterly dumb.
Customers who will use a product don’t want to have more features or more lines of code but they want their problem to be solved. The ultimate value is in understanding the problem and providing solutions that effectively address it.
Less is more mantra has been heard for years. But it’s not necessarily about minimalism, but more about understanding the business hypothesis, the context, the customer and the problem and proposing a solution that works. Sometimes it will be “less is more”. Sometimes the outcome will be quite stuffed. Almost always the best solution will be different that the one envisioned at the beginning.
I sometimes use a very simple, and not completely made up, example. Let’s assume you talk to a team that is twice as expensive as your reference team. They will, however, guide you through the product development process, so that they’ll end up building only one third of the initial scope. It will be enough to validate, or more likely invalidate, your initial business hypothesis. Which team is ultimately cheaper?
They first team is not cheaper if you take into account the cost of developing an average feature. Feature development is, however, neither the only nor the most important outcome they produce. Looking from that perspective the whole equation looks very differently, doesn’t it?
This is a way of showing that in every deal we trade different currencies. Most typically, but not necessarily so, one of these currencies is money. We already touched two more: functionality or features and validation of business hypothesis. We could go further: code quality, maintainability, scalability, and so on and so forth.
Now, it doesn’t mean that all these currencies are equally important. In fact, to stick with the example I already used, rapid validation of business hypothesis can be of little value for a client who just needs to replace an old app with a new one, that is based on the same, proven business model.
In other words in different situation different currencies will bear different value for a purchasing party.
The same is true for the other side of the deal. It may cost us differently to provide a client scalable application than to build a high quality code. This would be a function of skills and experience that we have available at the company.
The analogy goes even further than that. We can pick any currency and look how much each party values that currency. The perception of value will be different. It will be different even if we are talking about the meta currency—money.
If you are an unfunded startup money is a scarce resource for you. If at the same time we are close to our ideal utilization (which is between 80% and 90%) additional money we’d get may not even be a good compensation for lost options and thus we’d value money much less than you do.
On the other hand, if your startup just signed round B funding abundance of available money will make you value it much less. And if we just finished two big projects and have nothing queued up and plenty developers are slacking then we value money more than you do.
This is obviously related to current availability of money and its reserves (put simply: wealth) in a given context. Dan Kahneman described it with a simple experiment. If you have ten thousand dollars and you get a hundred dollars that’s pretty much meh. If you have a hundred dollars and you get a hundred dollars, well, you value that hundred much, much more.
Those two situations create a very different perception of the offer one party provides to the other. They also define two very different business environments. In one it is highly unlikely that the collaboration would be satisfying for both parties, even if it happens. In the other, odds are that both sides will be happy.
This observation creates a very interesting dynamics. The most successful deals will be those when each party trades currency that is low-valued for the one that is valued highly.
In fact, it makes a lot of sense to be patient and look for the deals where there is a good match on this account than to jump on anything that seems remotely attractive.
Such an attitude requires a lot of organizational self-consciousness on both sides. At Lunar Logic we think of ourselves as of product developers. It’s not about software development or adding features. It’s about finding ways to build products effectively. It requires broader skills set and different attitude. At the same time we expect at least a bit of Lean Thinking on account of our clients. We want to share understanding that “more code” is pretty much never the answer.
Only then we will be trading the currencies in a way that makes it a good deal for parties.
And that’s exactly the pattern that I look for whenever I say “value for money.”
Minimal Viable Product (MVP) is such a nice idea. Let’s build something that is as small as possible and at the same time viable, which translates to “provides value and thus make sense to build it.” Two adjectives in a mix where one counterbalances the other and vice versa.
Since I currently run a web software house I hear the term MVP very frequently. Or to be precise I hear the term MVP being abused very frequently. On some occasion the viable part would be ignored. Much more frequently though the way people understand MVP has virtually nothing to do with the minimal part.
During the early discussions about products our potential clients want to build I would typically ask about a business case behind a project or an app. It’s not about what it is that someone wants to build. It’s about why it is worth building that thing in the first place.
Note, I’m not judgmental. We contributed to better or worse ideas but I don’t reserve the right to know what’s worth building and what’s not. In fact, my questions have a very different purpose. What I want to achieve is to learn the value behind the app so that we can have a meaningful discussion about stuff in a backlog.
Now, this is the part where typically I’d really like to have people read Lean Startup before they are even allowed to talk to any software shop about building their product. And then, read it once again to understand what they are reading in depth.
The reason is that most of the time I can instantly come up with a batch of work that is one third, one fifth or one tenth of what was labelled an Minimal Viable Product by a potential client and it would still validate a business hypothesis behind a product. It likely means that with a bit of effort and better understanding of the context our clients would be able to cut it down way further than that. It may mean that they’d be even able to validate the basic idea without writing any software at all.
These so called “MVPs” wouldn’t recognize a real Minimal Viable Product even if it kicked them in the butt.
A sad part is that most of the time discussion around what really is minimal is futile. While I can provide my insight and encourage to learn more about the topic an argument often boils down to “we really need to build it all because, well, we don’t believe anything short of that would work.”
The long story short, I believe that MVP is in the top 5 most abused terms in our industry. By now referring to MVP is mostly meaningless unless you ask a series of questions to understand what one means by that. We could have skipped he MVP part, have the same discussion and we’d save a little bit of time.
That’s why I believe we need another frame for discussing what the initial increment of a product is.
What I caught myself on a number of times was proposing our clients a different constraint. Let’s step aside from discussing what is minimal and what is viable. Let’s figure out which features will be the part of the product in every single, even most crazy, scenario that we can think of. And I really mean every single one of them.
What I try to achieve with this discussion is to find the set of features that is a common denominator for all the options of building the product. There’s always something like that. A core process that the app support. A basic idea that the app is built upon. An ultimate issue that the app attempts to solve.
What I don’t expect is to see the full solution, even the most basic one. It would be an MVP on its own and we’d be back to the square one. What I expect is just a bunch of bits and pieces that are required to eventually build the app.
It is neither minimal nor viable.
It is indispensable though.
There are a couple of reasons to do that. The first one is that it reframes how both parties, the client and us, think of a product. We don’t try to settle on what is viable and what is minimal. We simply go with something that we know will be useful.
The other one is that it addresses the huge challenge of building a relationship. In fact this part goes really deep. It typically starts with a question how much building something would take. Some sort of an estimate. Well, it’s another thread. I’m not fundamentally against the estimates and see value in understanding generally how much something would take. At the same time I acknowledge that humans are simply not well equipped to estimate as we can’t learn to assess stuff in abstract measures. At the end of the day though, the smaller the batch size of work the smaller the potential risk and the smaller the estimation mistake.
In other words the smaller the initial batch of work the easier it is to start working.
It is true from another perspective as well. The most important modifiers of the cost of building a product in a client-vendor scenario isn’t anything related to the product itself. It is the quality of collaboration. It’s about both parties feeling like they’re the part of the same team. It’s about short feedback loops. It’s about working together toward the goal.
Unless it is about lack of transparency, distrust, and exploiting the other party.
The tricky part here is that you don’t know where at this spectrum you are until you start working. Building the smallest possible batch of work together pretty much gives you all the knowledge you needed. Seriously, you don’t need more than just few weeks to get a good feeling where collaboration part is going.
That’s why this the idea of Minimal Indispensable Feature Set is so useful whenever more than a single party is involved in building a product.
Minimal Indispensable Feature Set is perfectly aligned with building an MVP. In fact it is a subset of an MVP. At the same time it addresses the part of the setup that goes way beyond simply defining of what product is.
We live in a world where more and more frequently the building part is outsourced to another party. Getting the collaboration right at least as critical as getting the product idea right.
Almost every time I’m talking about measuring how much time we spend on value-adding tasks, a.k.a. value, and non-value-adding stuff, a.k.a. waste, someone brings an example of refactoring. Should it be considered value, as while we refactor we basically improve code, or rather waste, as it’s just cleaning after mess we introduced in code in the first place and the activity itself doesn’t add new value to a customer.
It seems the question bothers others as well, as this thread comes back in Twitter discussions repeatedly. Some time ago it was launched by Al Shalloway with his quick classification of refactoring:
The three types of refactoring are: to simplify, to fix, and to extend design.
Obviously, such an invitation to discuss value and waste couldn’t have been ignored. Stephen Parry shared an opinion:
One is value, and two are waste. Maybe all three are waste? Not sure.
Not a very strong one, isn’t it? Actually, this is where I’d like to pick it up. Stephen’s conclusion defines the whole problem: “not sure.” For me deciding whether refactoring is or is not value-adding is very contextual. Let me give you a few examples:
You build your code according to TDD and the old pattern: red, green, refactor. Basically refactoring is an inherent part of your code building effort. Can it be waste then?
You change an old part of a bigger system and have little idea what is happening in code there, as it’s not state-of-the-art type of software. You start with refactoring the whole thing so you actually know what you’re doing while changing it. Does it add value to a client?
You make a quick fix to code and, as you go, you refactor all parts you touch to improve them, maybe you even fix something along the way. At the same time you know you could have applied just a quick and dirty fix and the task would be done too. How to account such work?
Your client orders refactoring of a part of a system you work on. Functionality isn’t supposed to be changed at all. It’s just the client suppose the system will be better after all, whatever it means exactly. They pay for it so it must have some value, doesn’t it?
As you see there are many layers which you may consider. One is when refactoring is done – whether it’s an integral part of development or not. Another is whether it improves anything that can be perceived by a client, e.g. fixing something. Then, we can ask does the client consider it valuable for themselves? And of course the same question can be asked to the guys maintaining software – lower cost of maintenance or fewer future bugs can also be considered valuable, even when the client isn’t really aware of it.
To make it even more interesting, there’s another advice how to account refactoring. David Anderson points us to Donald Reinertsen:
Donald Reinertsen would define valuable activity as discovery of new (useful) information.
From this perspective if I learn new, useful information during refactoring, e.g. how this darn code works, it adds value. The question is: for whom? I mean, I’ll definitely know more about this very system, but does the client gets anything of any value thanks to this?
If you are with me by this point you already know that there’s no clear answer which helps to decide whether refactoring should be considered value or waste. Does it mean that you shouldn’t try sorting this out in your team? Well, not exactly.
Something you definitely need if you want to measure value and waste in your team (because you do refactor, don’t you?) is a clear guidance for the team: which kind of refactoring is treated in which way. In other words, it doesn’t matter whether you think that all refactoring is waste, all is value or anything in between; you want the whole team to understand value and waste in the same way. Otherwise don’t even bother with measuring it as your data will be incoherent and useless.
This guidance is even more important because at the end of the day, as Tobias Mayer advises:
The person responsible for doing the actual work should decide
The problem is that sometimes the person responsible for doing the actual work can look at things quite differently than their colleague or the rest of the team. I know people who’d see a lot value in refactoring the whole system, a.k.a. rewriting from scratch, only because they allegedly know better how to write the whole thing.
The guidance that often helps me to decide is answering the question:
Could we get it right in the first place? If so then fixing it now is likely waste.
Actually, a better question might start with “should we…” although the way of thinking is similar. Yes, I know it is very subjective and prone to individual interpretations, yet surprisingly often it helps to sort our different edge cases.
An example: Oh, our system has performance problems. Is fixing it value or waste? Well, if we knew the expected workload and failed to deliver software handling it, we screwed this one up. We could have done better and we should have done better, thus fixing it will be waste. On the other hand the workload may exceed the initial plans or whatever we agreed with the client, so knowing what we knew back then performance was good. In this case improving it will be value.
By the way: using such an approach means accounting most of refactoring as waste, because most of the time we could have, and should have, done better. And this is aligned with my thinking about refactoring, value and waste.
Anyway, as the problem is pretty open-ended, feel invited to join the discussion.
Often, when I’m working with teams that are familiar with Scrum, they find the concept of cadence new. It is surprising as they are using cadences, except they do it in a specific, fixed way.
Let’s start from what most Scrum teams do, or should do. They build their products in sprints or iterations. At the beginning of each sprint they have planning session: they groom backlog, choose stories that will be built in the iteration, estimate them etc. In short, they replenish their to do queue.
When the sprint ends the team deploys and demos their product to the client or a stakeholder who is acting client. Whoever is a target for team’s product knows that they can expect a new version after each timebox. This way there is a regular frequency of releases.
Finally, at the very end of the iteration the team runs retrospective to discuss issues and improve. They summarize what happened during the sprint and set goals to another. Again, there is a rhythm of retrospectives.
Then, the next sprint starts with a planning session and the whole cycle starts again.
It looks like this.
All practices – planning, release and retros – have exactly the same rhythm set by the length of timebox. A cadence is exactly this rhythm.
However, you can think of each of practices separately. Some of us got used to the fact that frequency of planning, releases and retrospectives is exactly the same, but when you think about this it is just an artificial thing introduced by Scrum.
Would it be possible to plan every second iteration? Well, yes, why not? If someone can tell in advance what they want to get, it shouldn’t be a problem.
Would it be a problem if we had planning more often then? For many Scrum teams it would. However, what would happen if we planned too few stories for the iteration and we would be done halfway through the sprint? We’d probably pull more stories from backlog. Isn’t that planning? Or in other words, as long as we respect boundaries set by the team, wouldn’t it possible to plan more frequently?
The same questions you can ask in terms of other practices. One thing I hear repeatedly is that more mature teams change frequency of retrospectives. They just don’t need them at the end of every single sprint. Another strategy is ad-hoc retro which usually makes them more frequent than timeboxes. Same with continuous delivery which makes you deploying virtually all the time.
And this is where the concept of cadence comes handy. Instead of talking about a timebox, which fixes time for planning, releases and retrospectives, you start talking about a cadence of planning, a cadence of releasing and a cadence of retrospectives separately.
At the beginning you will likely start with what you have at the moment, meaning that frequencies are identical and synchronized. Bearing in mind that these are different things you can perfectly tweak them in a way that makes sense in your context.
If you have comfort of having product owner or product manager on-site, why should you replenish your to do queue only once per sprint? Wouldn’t it be better if the team worked on smaller batches of work, delivering value faster and shortening their feedback loops?
On the other hand, if the team seems mature frequency of retros can be loosened a bit, especially if you see little value coming out of such frequent retros.
At the same releases can be decided ad-hoc basing of value of stories the team has built or client’s readiness to verify what has been built or on weather in California yesterday.
Depending on policies you choose to set cadences for your practices it may look like this.
Or completely different. Because it’s going to be adjusted to the specific way of working of your team.
Anyway, it is likely, that the ideal cycle of planning, releases and retrospectives isn’t exactly the same, so keeping cadences of all of these identical (and calling them iteration or timebox) is probably suboptimal.
What more, thinking about a cadence you don’t necessarily need them to be fixed. As long as they are somewhat predictable they totally can be ad-hoc. Actually, in some cases, it is way better to have specific practice triggered on event basis and not on time basis. For example, a good moment to replenish to do queue is when it gets empty, a good moment to release is when we have a product ready, which may even be a few times a day, etc.
Note: don’t treat it as a rant against iterations. There are good reasons to use them, especially when a team lacks discipline in terms of specific practices, be it running retros or regular deployments. If sprints work for you, that’s great. Although even then running a little experiment wouldn’t hurt, would it?
Software estimation. Ah, a never-ending story. Chances are good that, whenever you’re talking about building software, this subject will pop up soon. You can be pretty sure that basically everyone around has problems with estimation or simply struggles with it. And that’s virtually obvious that there would be a new sexy method of estimation every year or so. The method which is claimed to solve an unsolvable puzzle.
One of advices I shared was that whenever you can you should avoid estimation at all. This sprung sort of objection. OK, so the subject definitely is worth wider discussion.
First things first. Why do we estimate at all in the first place? Well, we usually want to know how much time it’s going to take to build this damn thing, don’t we? Um, have I just said “usually?” Meaning, “not always?” Actually yes. It’s not that rare when we either don’t need any estimate at all or we just want to have a general insight whether the project will be built in hours, days, weeks, months or years. In either of these cases just a coarse-grained wild-ass guess should be fine. If it’s needed at all.
OK, but what about majority of cases when we need some kind of real estimate? For example all those fixed price projects where estimates are basically a part of risk management, as the better the estimate is the smaller are chances that the project goes under water. I can’t deny that we need to have something better than wild-ass guess then.
Yet, we still can avoid estimating quite often.
Let me start with one of obvious things about estimation: if you base on historical data, and you apply them in a reasonable way of course, you can significantly improve your estimates. In other words, no matter the method, if you are just guessing how much something is going to take, you will likely to end up with way worse results when compared to a method, which uses your track record. And yes, I just dared to name planning poker “guessing.” It is collective, involves discussion, etc but usually it is just this: guessing.
Cool, let’s use historical data then. What’s next? My next question would be: how precise must your estimates be? Seriously, what kind of precision you aim for? My point is that we need very precise estimates very rarely. This is by the way the reason why I don’t use Evidence Based Scheduling anymore.
Anyway, ask yourself a question: how much you would pay for bringing your estimates to the next level of precision. Think of it like being correct in terms of estimating in years, months, weeks, days, hours, etc. Let’s take just an average several-month-long, fixed-priced type of project.
If I’m wrong with years I’m totally screwed, thus I’d pay significant part of project budget to be correct on such level. If I’m wrong with months it might be a hit on our reputation and also it may consume our whole profit we get of the project, so I’d be ready to invest something around the profit to be correct with months. Now weeks. Well, a week here, a week there, does it make such a difference in this kind of project? Can’t I just assume there is some variability here? Unless of course our deadlines are written in stone, e.g. you adjust your software to law changes. In most cases I’d invest just a handful of bucks here at best. Days? Hours? Are you kidding? Does it even make a difference that I spend a day more on such project?
Now you know what kind of precision you expect from your estimates. Would it be possible for you to come up with estimates of such precision basing purely on historical data? I mean, can’t you just come up with a simple algorithm which automatically produces results reasonable enough that you can forget about all the effort spent on estimation?
Whenever we come to discussing estimation I like to share the story from one of my teams: basing on a fact that we were collecting data on our cycle times and we reduced variability in task sizes coming up with the idea of standard-sized features we were able to do a very good job with estimates not estimating at all. We were simply breaking work down so we could learn how many features there are to build and then we were using very simple metrics basing on our track record to come up with the numbers our sales department requested. By the way: a funny thing is, almost all of that appeared as an emergent behavior – something we started doing as a part of continuous improvement initiative.
Either way, even though we were capable of providing reasonably precise and reliable estimates we didn’t really estimate. I was surprised how easy it was to get rid of estimation, but then I can come back to the point from the beginning of the article: what is the point of estimation? You don’t do it just for the sake of performing the task; you do it for a reason. As long as you achieve your goal, does the method really matter? It means that you can get rid of estimating even if you do need some kind of estimates.
In my story from Lean Kanban Central Europe 2011 I promised I will elaborate more on my session there, titled Kanban Weak Spots. The starting point to the session was analysis of a number of situations where Kanban didn’t really work, finding out a root cause and then trying to build a bunch recurring patterns from that.
By the way I have an interesting observation. Whenever I called for Kanban failure stories I heard almost perfect silence as an answer. It seems everyone is so damn good with adopting Kanban that it virtually never fails.
Except I’ve personally seen a bunch of failed Kanban implementations. Either I’m the most unlucky person in the world and saw all of Kanban failures out there or for some reason we, the Kanban crowd, are still sharing just success stories and not putting enough attention to our failures.
Actually, when I was discussing the session with fellow presenters we quickly came to the point that basically every time we think about Kanban failures it can be boiled down to people. However, and it is one of recurring lessons from lkce11, we should address vast majority of ineffectiveness to the system, not to the people. In other words, yes, Kanban fails because of people, but we change the system and only this way we influence people behavior.
This is exactly the short version of the presentation, inspired by Katherine Kirk and Bob Marshall.
There is the long version too. Symptoms, which show you that something isn’t working, and if you do nothing about them you’re basically asking for failure. I have good news though. Most of the time you will look for these symptoms in just one place – on your Kanban board.
Probably the most common issue I see among Kanban teams is not keeping the board up to date. In short, it means that the board doesn’t reflect the reality and your team is making their everyday project decisions basing on a lie. A very simple example: given that there is a bottleneck in testing but it isn’t shown on a Kanban board, a developer would come to the board to see what’s next and they would decide to start building a new feature instead of helping to sort bottleneck out. Instead of making things better they would make them even worse, thanks to the board which isn’t up to date.
I face the same problem but on a different level, whenever a team tries to make a board showing the way they’d like to work, and not the way they really work. Actually this one is even worse – not only do you make your everyday decisions basing on a lie again but it’s also more difficult to get things back on the right track again. This time it’s not enough to update the sticky notes – you need to fix the design of the board too.
Another board-related issue would be forgetting about a good old rule: KISS. When people learn all these nice tricks they can use on their boards they’re inclined to use a lot of them. Often way too many. They end up over-engineering the board, which means that they bury important information under the pile of meaningless data. Soon, people aren’t able to tell what means what and which visual represent which situation. Eventually, they stop to care to update the board because they’re basically lost, so they’re back to the square one.
Violating limits has its own place in hell. Of course it is a matter of your policies whether you allow abusing limits at all. However it is pretty common situation that it is generally acceptable that limits are violated very often, or even all the time. Now, let me stress this: limits in Kanban are the fuel of improvements; if you don’t treat your limits seriously you don’t treat improvement seriously either. Limiting work in progress is a mechanism, which makes people act differently than they normally would. When a developer, instead of starting to build another feature, goes to help with a blocker in testing it is usually because limits told them so. Eventually they learn to predict such situations and act even earlier, before they fill up the work queue. Anyway it all starts with simple actions, which are triggered by limiting WIP.
The interesting thing is that all these problems can be seen on a Kanban board. The reason is pretty simple: the board should reflect the reality, no matter how sad the reality is. You deal with lousy process the same way as you deal with alcoholism: the first step is admitting you have a problem. Even if your process looks like a piece of crap show it on your Kanban board. Otherwise you’re just cheating yourself and you aren’t even starting your journey with continuous evolution toward perfection.
There is however one driver of Kanban failure, which won’t be seen on a Kanban board. It’s also my recent pet peeve. Treating Kanban as a project management or a software development approach is basically begging for failure. It is asking Kanban to deal with something which it wasn’t designed for. It’s using a banana to hammer a nail. Seems funny indeed, but if you care about a success, well, then good luck – you’re going to need a lot of it.
Kanban can be called change management approach or process-driving tool or even improvement vehicle but it doesn’t say a word on how you should manage your projects or build your software. If you don’t build Kanban on a top of something, be it a set of best engineering practices or project management method of your choice, you’re likely to fail miserably. And then you will be telling everyone that you need to have experienced team to start using Kanban and that it wouldn’t work otherwise.
So here it is – a handful of risks you should take into consideration whenever adopting Kanban in your team. A bunch of situations observed by the most unlucky guy in the world, who actually sees Kanban failures on occasions. However, what I want to achieve with this post is not to discourage you to try Kanban out. Pretty much the opposite. I want you to think of this list and actively work to avoid the traps. I just want you to succeed.
And this is why you will hear me writing and speaking about Kanban weak spots again.
Now, even though I teased much of the content from my lkce11 session above, here are my slides.
By the way, if you happened to be on my session in Munich please rate it.
If you’d like to see some more content on the subject, fear not. As I’m very passionate about that I will definitely write more on this soon.
Advertisement: Want to have such nice Kanban boards in your presentations or blog posts as well? Check InfoDiagram Kanban Toolbox. Use pawelBBlog code to get $10 discount.