

The last couple of years have been riddled with speculations about how AI will change the world. Software development and the broader IT industry are among the most affected contexts. Things are changing. The future is uncertain.
In such a landscape, it’s easy to subscribe to any speculation, like the infamous doom and gloom Citrini prediction. Before we fall for that, though, let’s look at the historical data.
It’s Q2 2026. If the AI predictions had been correct, then:
- We have AGI. As Sam Altman predicted.
- Thus, most developers don’t code anymore. That’s Matt Garman from two years ago.
- Why would they? After all, no one learns to code these days, because “everybody is now a programmer.” Courtesy of Jensen Huang.
- If you want concrete data, since last autumn, AI writes 90% of the code. Yup, that’s Dario Amodei.
- No one drops a tear over developers, though, because we already see how AI is in the midst of wiping out half of entry-level white-collar jobs. That’s Dario Amodei, too.
Yeah, I get your skepticism. That’s not reality I see around either. Fear not, however. Software engineers will go extinct this year. This time for real, says Dario Amodei. This time, we can trust him. For sure. Probably. Maybe.
Each time such an alarmistic prediction emerges, I ask one question: If X is true, what does the endgame look like?
What Is the Endgame?
I borrowed the idea of endgame from gaming, duh! Some gaming genres are built around a character progression. However, when a player character reaches the maximum level, the original game engine ceases to work. There’s no more level to grind. No more progression to make.
Thus, the endgame content was born. These are parts of a game designed specifically for max-level characters to keep the players interested. Typically, these are increasingly challenging. This time, the goal is not progress, but mastery. It’s like a game in a game.
The endgame content responds to the question of a hypothetical newbie player: “What happens if I play this game and keep progressing with my character?”
The question is interesting because we can envision the progression and intuitively realize that it can’t last indefinitely. At some point, an external constraint would impose itself, and our linear approximation of the trend (leveling up in this case) would break.
Thus, the question: What does the endgame look like?
The Endgame Question Is More Than Relevant in Business
If we look at market trends, the dynamics are surprisingly analogous. It’s not a game, so we don’t control the trends, but they’re there, sure enough. And they can’t last indefinitely. There’s always an external constraint that will impose itself.
The market share can’t go higher than 100%. The exponential growth can’t last more than a few years. Businesses need to make a profit eventually. And so on.
Now, if we ask the right questions, we don’t need to wait for the change to happen to see how the landscape will evolve. Better yet, we might see other facets of the change. Think of it as ripple effects. Then, suddenly, the landscape is richer, and we may come to very different conclusions from those we’d make if we looked at a trend in isolation.
A good example is what’s been dubbed a SaaSpocalypse—a recent devaluation of many SaaS businesses. What some perceived as the new trend predicting the end of SaaS, I consider merely a regression to the mean.
If this trend continued, the purchase price of these “old-school” product companies would be a bargain. They have healthy financials. Some have just recorded the best year ever. Unlike some of the tech scene darlings, they’re making actual profits. Plenty of them. Fundamentally, little has changed for these companies short- and mid-term.
It’s then relatively easy to see the endgame. The trend won’t continue too far, as eventually it would mean buying a dollar for fifty cents.
The Interconnected Trends and Second-Order Consequences
The endgame question is even more interesting whenever there’s no obvious limiting condition (like “you can’t have more than 100% of market share”). A good example is how AI affects coding.
We see increasing AI use in code generation. It’s not anywhere close to 90%, sure, but no one challenges that we’re doing more of that. Also, it’s obvious that AI agents can generate tons of code. And then some. No sweat.
The trend, then, suggests that we will have more and more of AI-generated code. Let’s then draw the trend line to the future and ask: What does the endgame look like?
Given how increasingly useful AI tools are, there’s no stopping the trend. At this pace, we will soon generate more code than we can reasonably review as we go. Once we stop the just-in-time code review, we will lose comprehension of what’s at the code level in our products.
The endgame is either a lights-out codebase or a risk of being outpaced by competitors. That’s an interesting dilemma. So far, research suggests that AI models are incapable of maintaining code in the long run. Yet, the business risk coming from potential competitors is real, too.
These are second- or third-order consequences of code-generation capabilities we have thanks to AI tools. And these are precisely the considerations that any product business should take into account these days.
These are far more interesting than boasting about how much code is AI-generated. As a customer, I couldn’t care less whether you generate 30% of your code. Or 90%. Or none at all. I do care whether the product solves my problem now and whether it will be technically sustainable in a year from now.
And you don’t hear Satya Nadellas and Mark Zuckerbergs of this world discussing their concerns about the maintainability of their products.
The Dynamics of the Endgame Question
The reason why the endgame question is so powerful is that it skips the current condition and jumps directly to the future state:
- What will be new or different once this new thing becomes the norm?
- When does the trend become unsustainable?
- How do correlated trends behave?
Think of it as a model. We look at one thing and have historical data on how it has behaved so far. Now, the simplest possible thing is to extend the trend line indefinitely into the future.
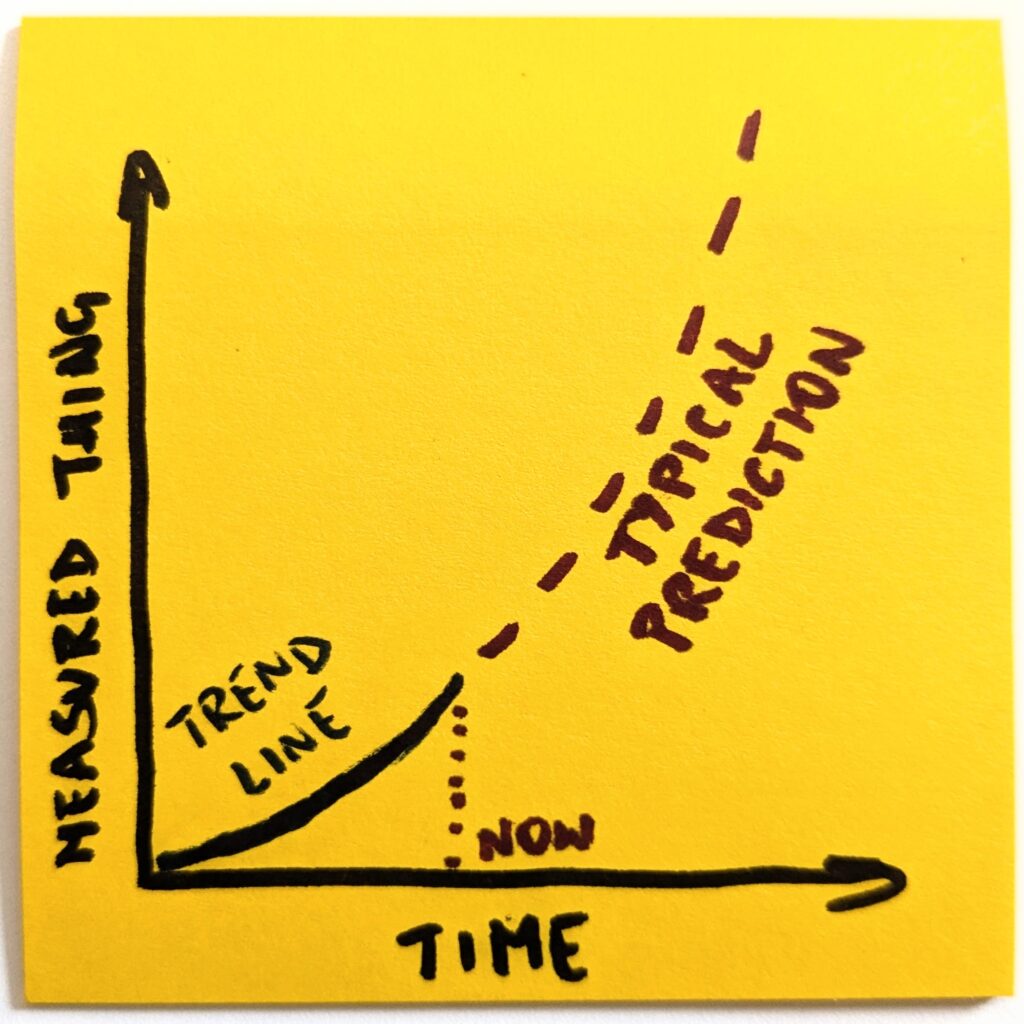
Except, as we already established, things do not work like this. In no reality does OpenAI have 8 billion paying ChatGPT users. So, before we predict the future, we consider external constraints.
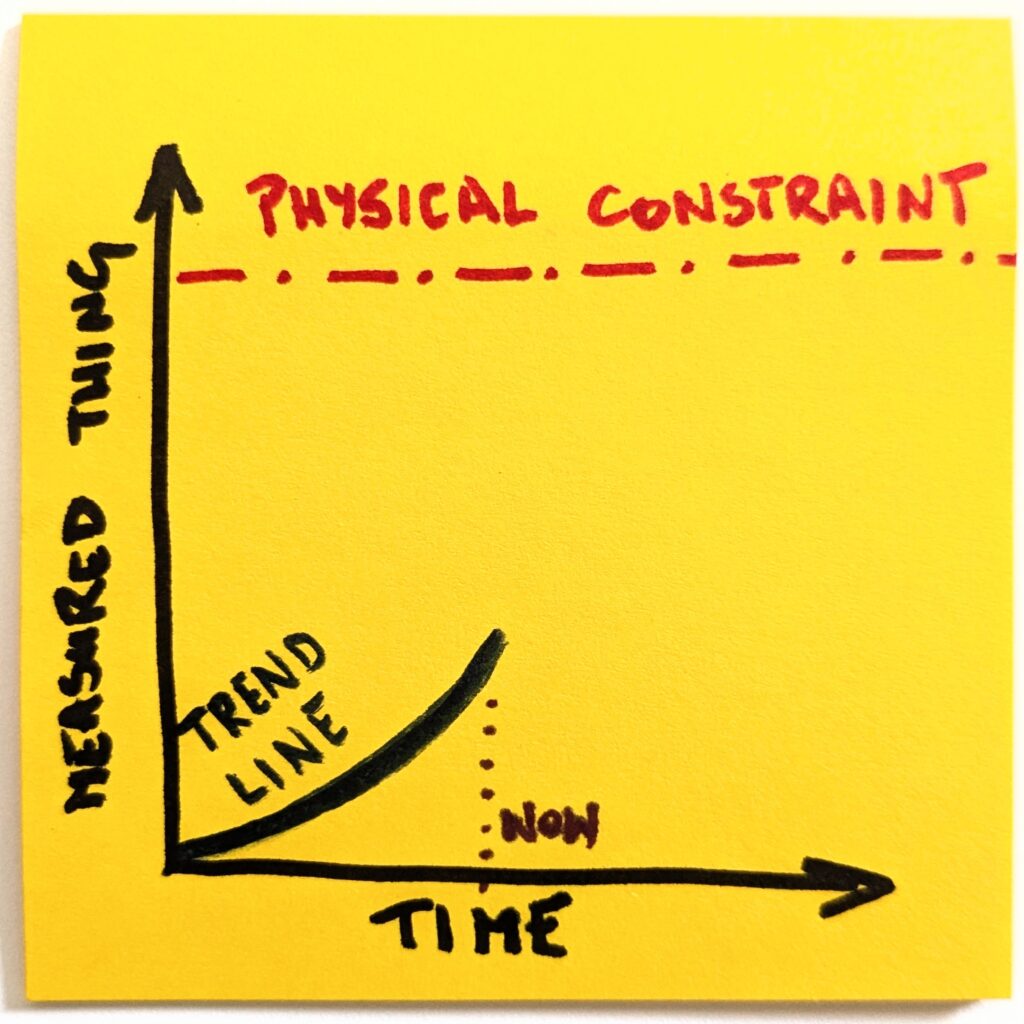
Once we make it explicit, it becomes obvious that a naive version of the future will not happen. Even if we assume the most optimistic scenarios, the trend line will have to change its shape.
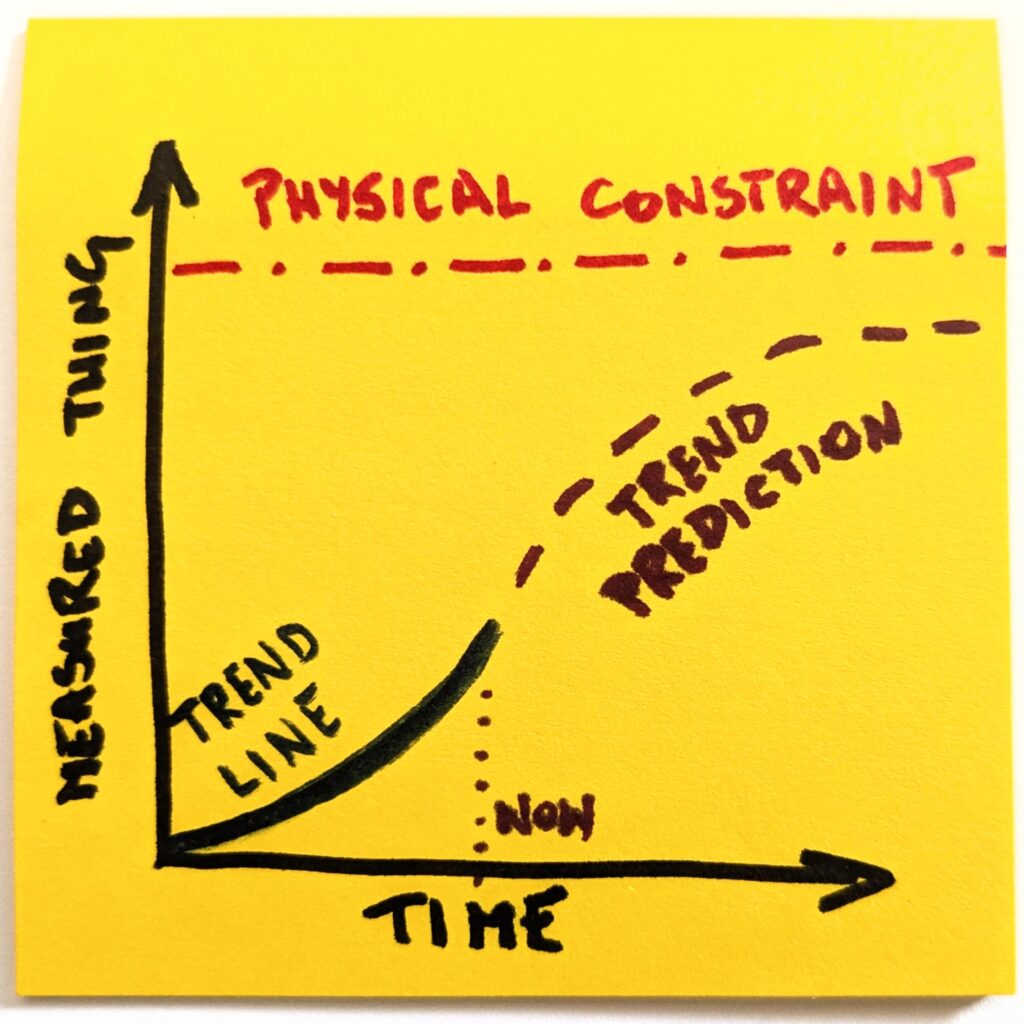
Well, that’s different now, thank you. But we’re not done yet. The most interesting things happen at the intersection. We can ask ourselves which other trends are correlated with whatever we focus on.
Like, if there’s more of this, there should also be more of that. Or vice versa, if there’s more of this, there should be less of that. As with our example, if we generate more and more code, there will necessarily be less technical comprehension. The stronger one is, the weaker the other will become.
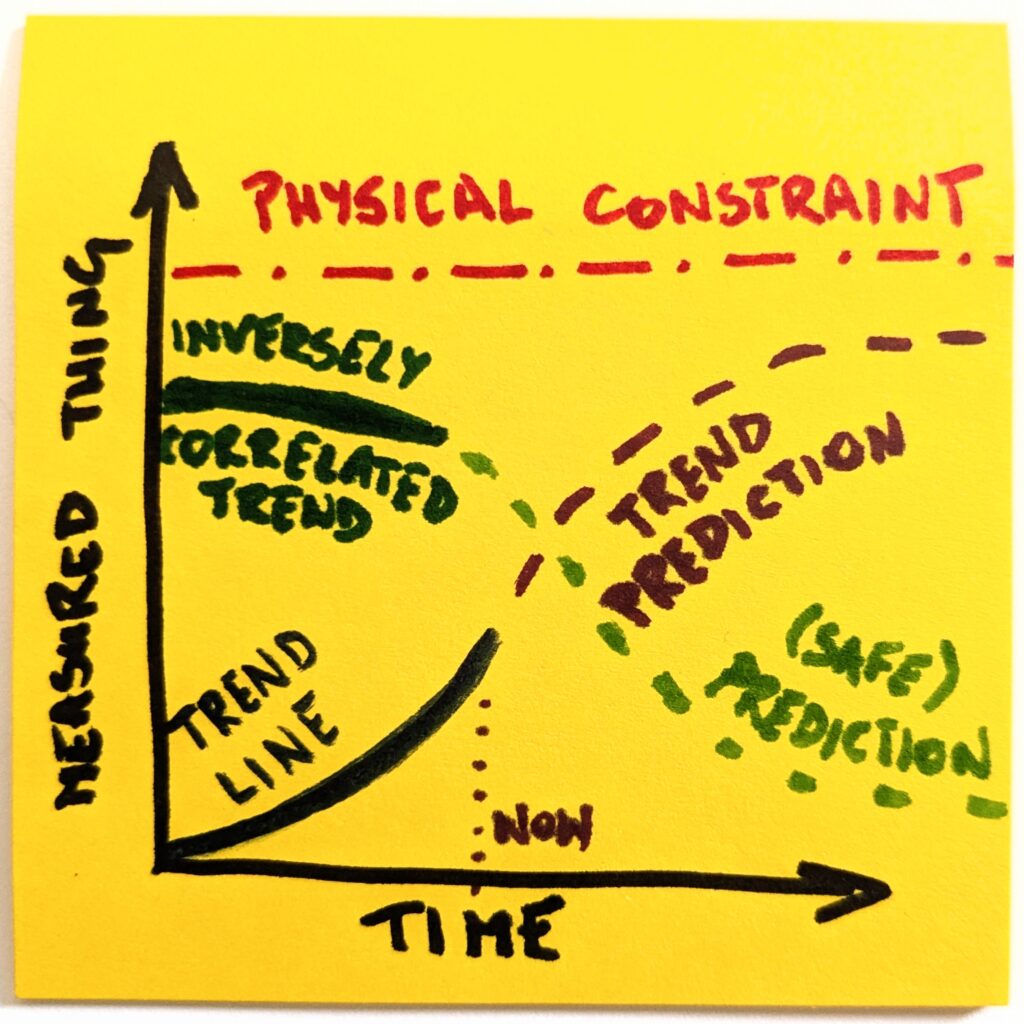
Since we already have a clearer picture of the landscape, it’s not that hard to predict how an inversely correlated thing will change. And to what degree. Suddenly, we are equipped to ask questions about second-order consequences.
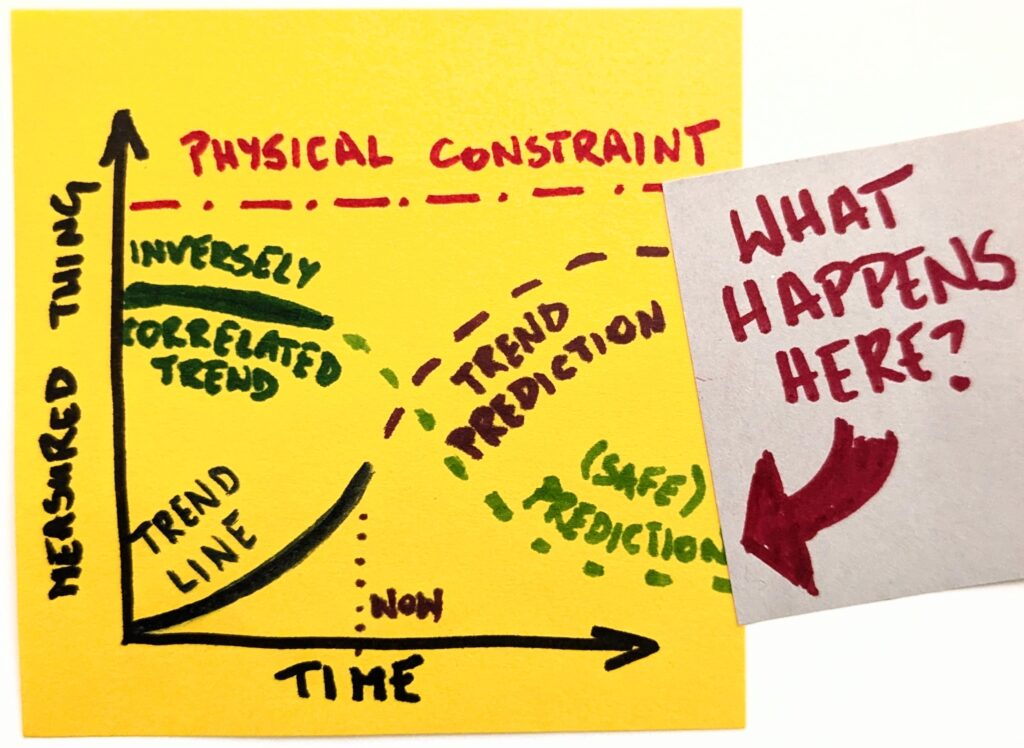
That’s where the endgame question shines. Instead of boasting about which big tech generates more code or predicting when developers go extinct, we may consider possible futures.
Human in the Loop and Coding
To run a quick example I touched on earlier, let’s consider AI and coding. Dario Amodei is wrong about how fast his AI models will take over coding. But it’s not because of the lack of capabilities of said models. I mean that too, but he knows more about these capabilities than you or me, and maybe he has all the right to believe it’s a technical problem that’s going to be fixed eventually.
He’s wrong because he considers code generation in a surprisingly isolated sandbox. If we were to believe Amodei’s predictions, we would have to assume that human-in-the-loop will be gone from software engineering.
I mean, physically, we can keep humans there, but they will have no real role. They’d be overloaded and incapable of good judgment. In fact, it’s already happening. Speculatively, though likely, in recent wars, humans-in-the-loop had the final call with decisions about strikes. Yet, you can’t expect good judgment if someone is expected to make 80 life-or-death decisions per hour.
There might still be a human body in the loop. The judgment, though? With enough cognitive load, it’s gone.
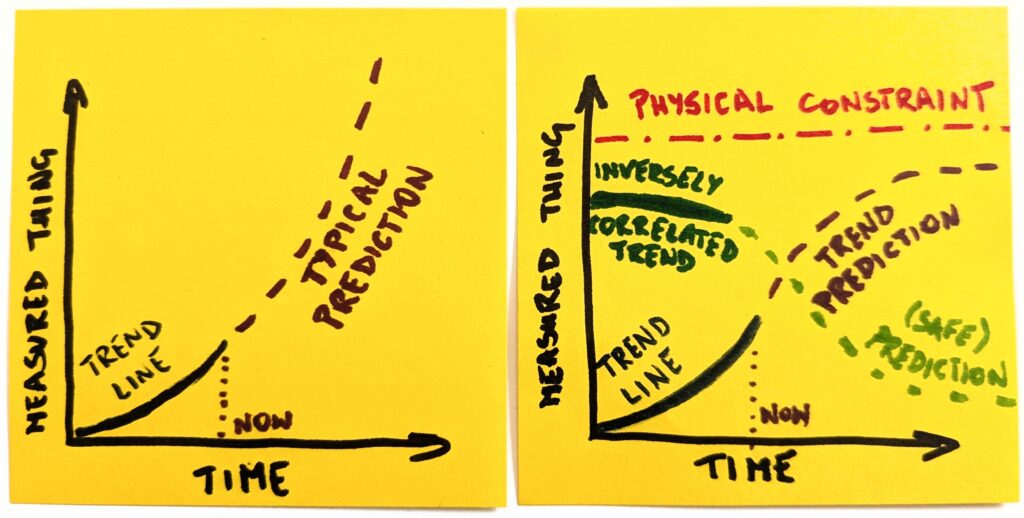
Just compare these two predictions. The first is a naive one, and considers a thing in isolation. The second attempts to understand what would change and how if the current trends stay with us. These two look very different.
The Endgame Question for Coding
So let’s look at what answers the endgame question yields in the coding example. In the past decades, we’ve been creating a growing amount of code. And yet, code review as a practice has also been increasingly popular.
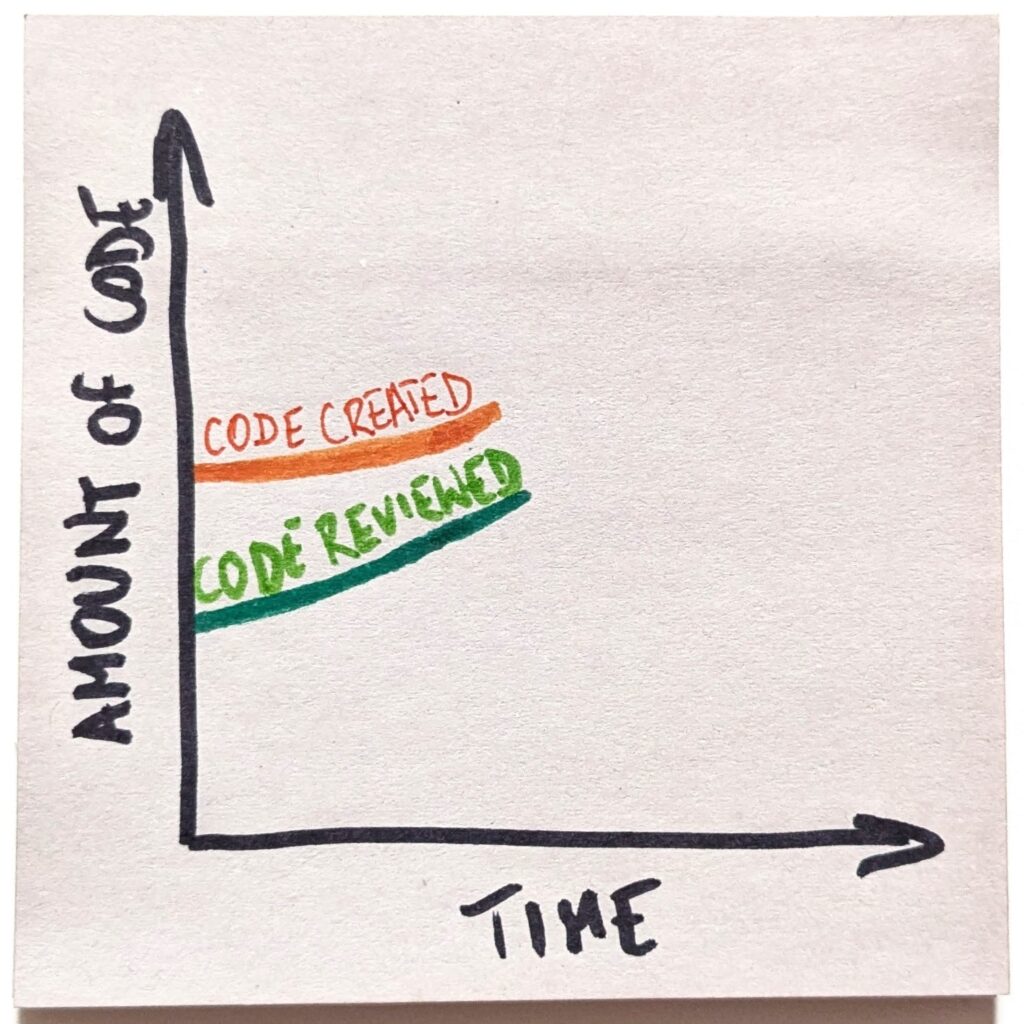
AI has introduced a foreign element to our system. Now we can easily generate as much code as we want. Increasingly, we do. That changes the current dynamics of software development trends.
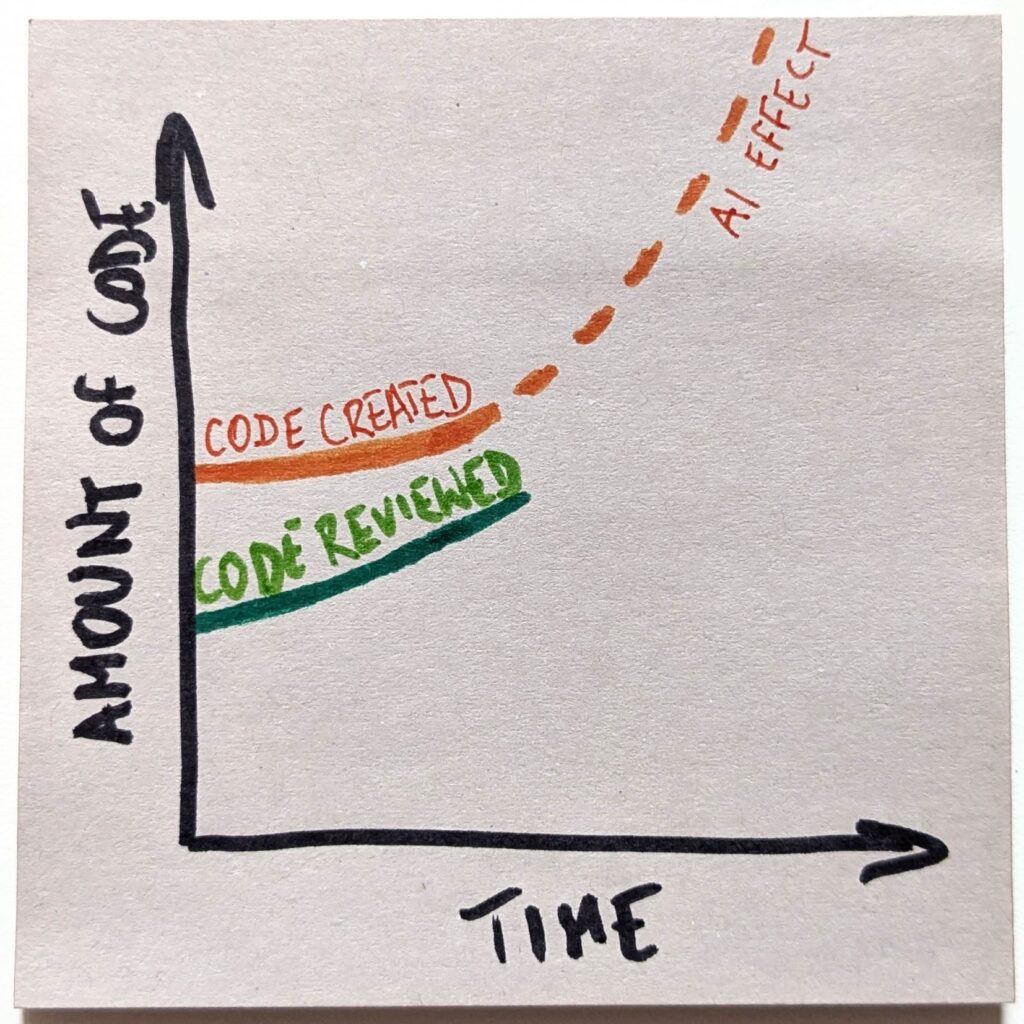
But wait, so far, the “code review” trend has been all good. The practice has been growing in popularity, despite the fact that, as a whole, we were developing more code.
Hell, one way of looking at it is that all code has been reviewed, since the developer creating it was doing a sort of review as part of the creative process.
The only problem is that code review is a cognitive task that requires attention. And we have a limited pool of it. If we suddenly needed to review 10x as much code, we don’t have enough engineers to handle that.
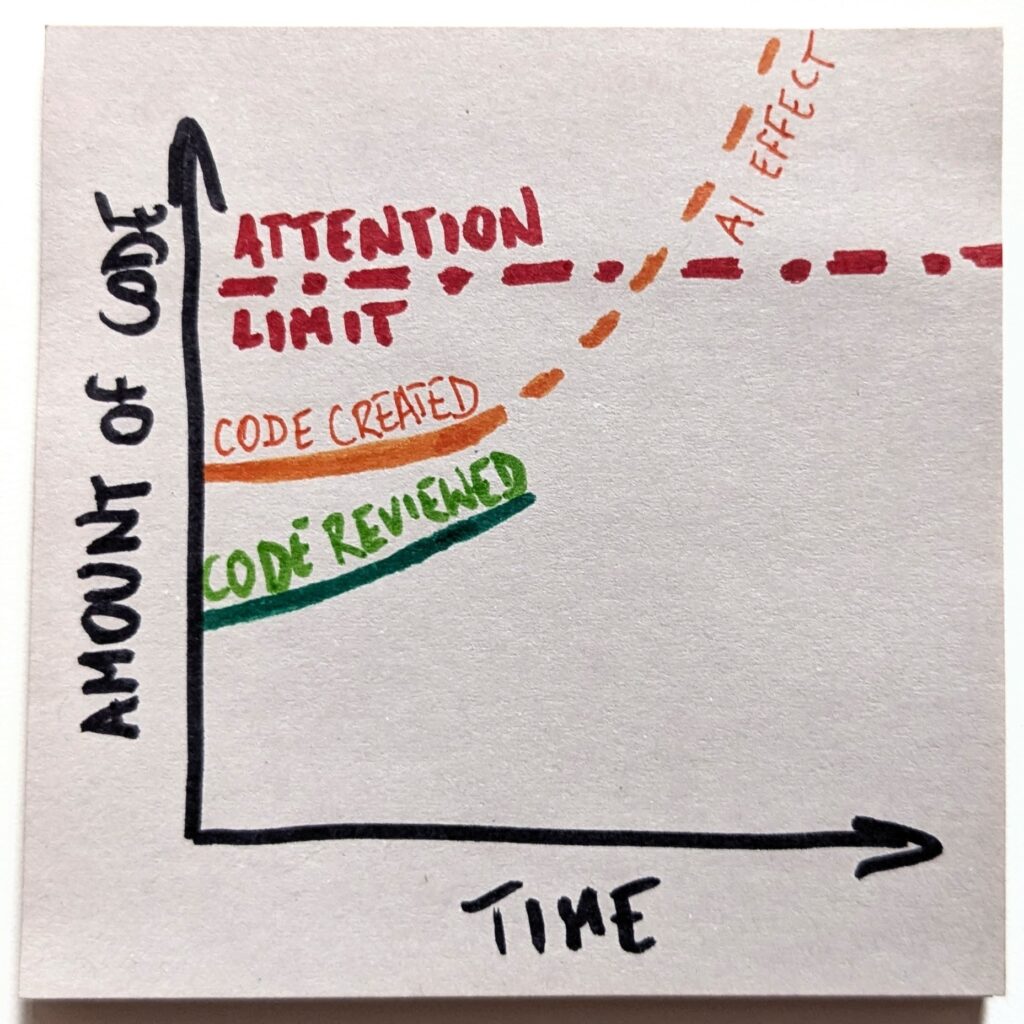
Even if we try to keep up, which I call an “optimistic” scenario here, we eventually hit the ceiling. There’s no more available attention to pay.
A side note: we could argue that we actually raise the limit by freeing developers from writing code, so they have more time to review it. That’s fair. However, we also claim we don’t need no new developers (so we don’t train them) and lay them off (so they change industries). Effectively, we’re working the limit line in both directions. In either case, even if it goes somewhat up, we’ll cross it soon enough.
With that, we’ll create a gap between the amount of code we create and the loads we are capable of reviewing. And that gap will only keep growing. Fast.
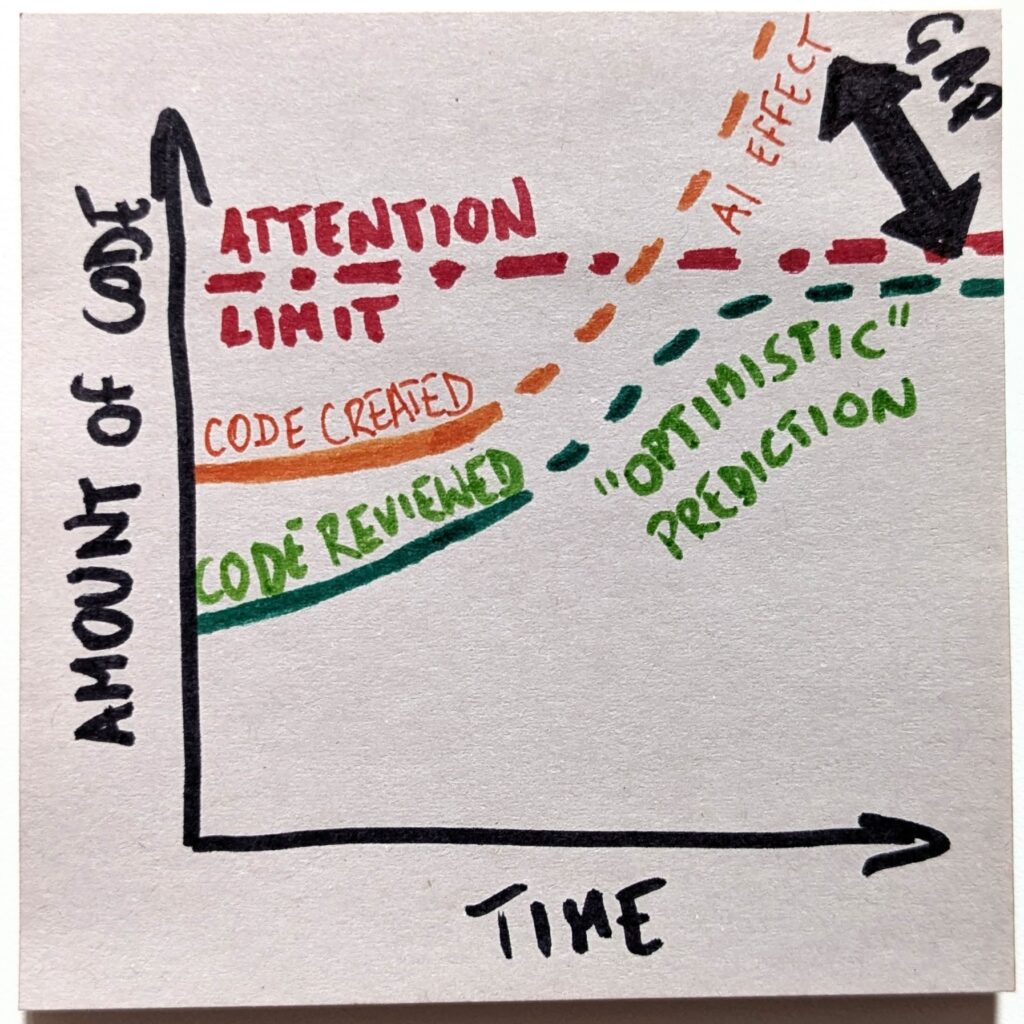
That, in turn, is the exact reason the “optimistic” scenario will not happen. Playing a losing game is no fun. Even less so if that’s an increasingly losing game. The only sensible expectation is that we will stop playing the game altogether.
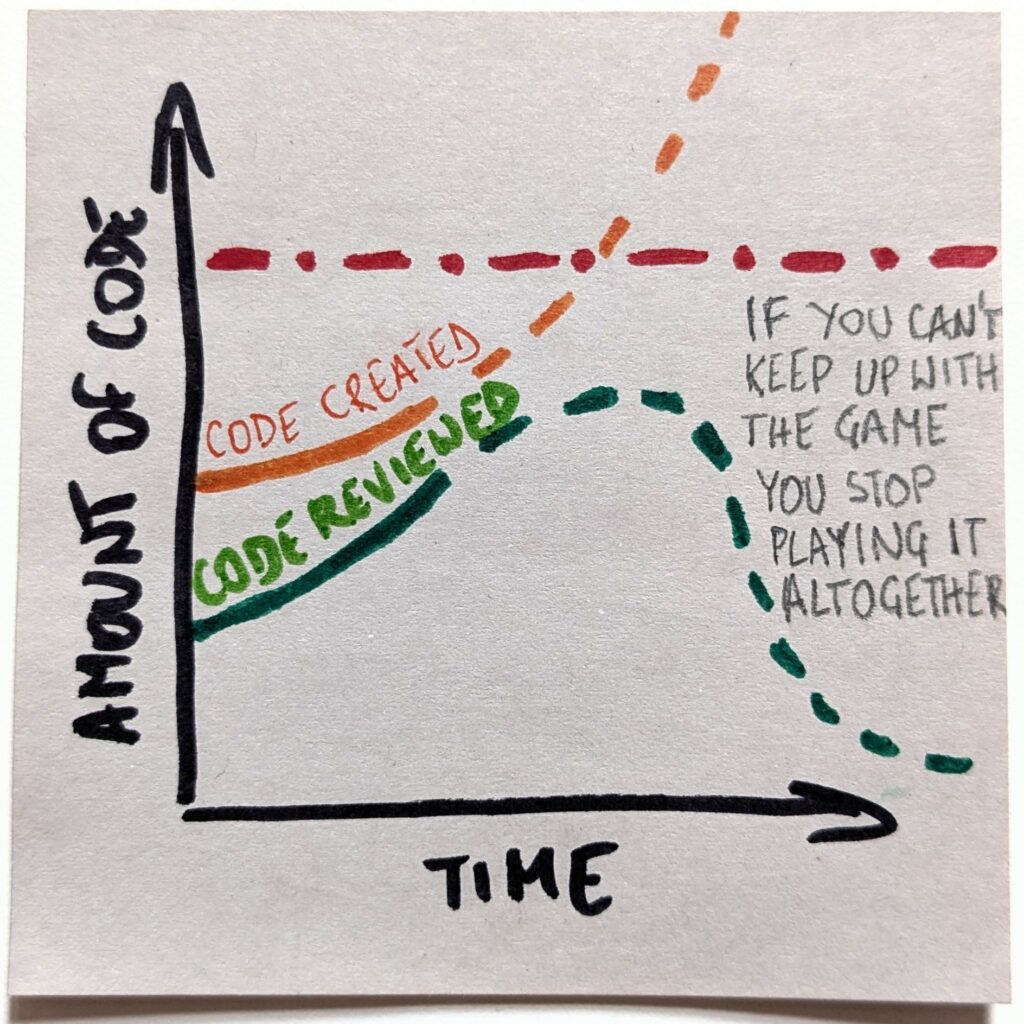
The new reality doesn’t mean stopping the reviews entirely. But we’ll need to pick our battles. And we’ll need to be increasingly picky about picking them. We’ll choose only the most critical parts of the code and maintain active knowledge of them.
Second-Order Consequences of the Coding Endgame
Things get even more interesting when we consider ripple effects. Before AI, basically, all the code was read. I mean, a human wrote it, so part of the process was looking at the thing. The “code read” curve was identical to the “code created” one.
However, as we stop writing code ourselves and expect the code review rate to nosedive, we’ll look at a completely different reality. “Code read” line will detach from “code created” and will follow “code reviewed.”

Now, that’s interesting. There is more code, but save for very few carefully chosen code bases, we neither read nor understand it. It’s as if there were islands of comprehension in a black-box ocean. That is, unless we fundamentally change something. So, are we ready to run critical systems on software we can’t comprehend? Because that’s what the endgame looks like.
And that’s but one example why the endgame question is such a neat trick. The moment we start asking it, we start seeing scenarios that go way beyond the hype. It’s not just “Claude Code is so awesome; it can do the coding for me.” It’s “Would I trust a vibe-coded e-commerce with my credit card number?” Or even “How would I feel if Visa or MasterCard ran on software no human comprehends?”
The Ultimate Question
Now, I know I rode the example of AI in coding in this post. The applicability of the endgame question is way broader, though. It literally pops up anytime someone makes a kind of bold prediction, well, about anything. You know, the type of “AI is capable of erasing half of white-collar jobs, so AI labs will get unfathomably rich,” or something along the same lines.
What does the endgame look like? Well, we make half of the knowledge workers unemployed, and who’s paying the AI bills, again?
Or take this: “AI will take over content generation as it can create 100x times as much as humans can, no sweat.” What does the endgame look like? We don’t have 100x as much attention, so the vast majority of the generated content will not be consumed at all. We may have the effect of bad money driving out good, but we won’t fundamentally have use of more content.
“Thanks to AI capabilities, we’ll see a surge of new products. Anyone will be able to run a product now.” What does the endgame look like? Again, the attention constraint (or the demography) suggests we won’t have 100x as many customers. So, if anything, we’ll just increase the failure rate. While running a startup is already unappealing, it will become even less of a winning proposition, which will actively drive people away from that path.
“AI will automate applying for jobs.” What does the endgame look like? Both sides get automated to handle an increasing load. Eventually, it’s one AI agent negotiating with another to figure out whether a human is a good fit for an organization. The system is bound to be misaligned and thus gamed. What follows is that we’ll either accept hiring candidates who are increasingly unfit for the role (but who played the game better) or reinvent the hiring system altogether.
So before we jump on another bit of “CEO said a thing” journalism, it’s worth asking: if that’s true, what does the endgame look like?
As hilarious as it would be, given the topic, this post has not been AI-generated. 웃 https://okhuman.com/wLBTwg







